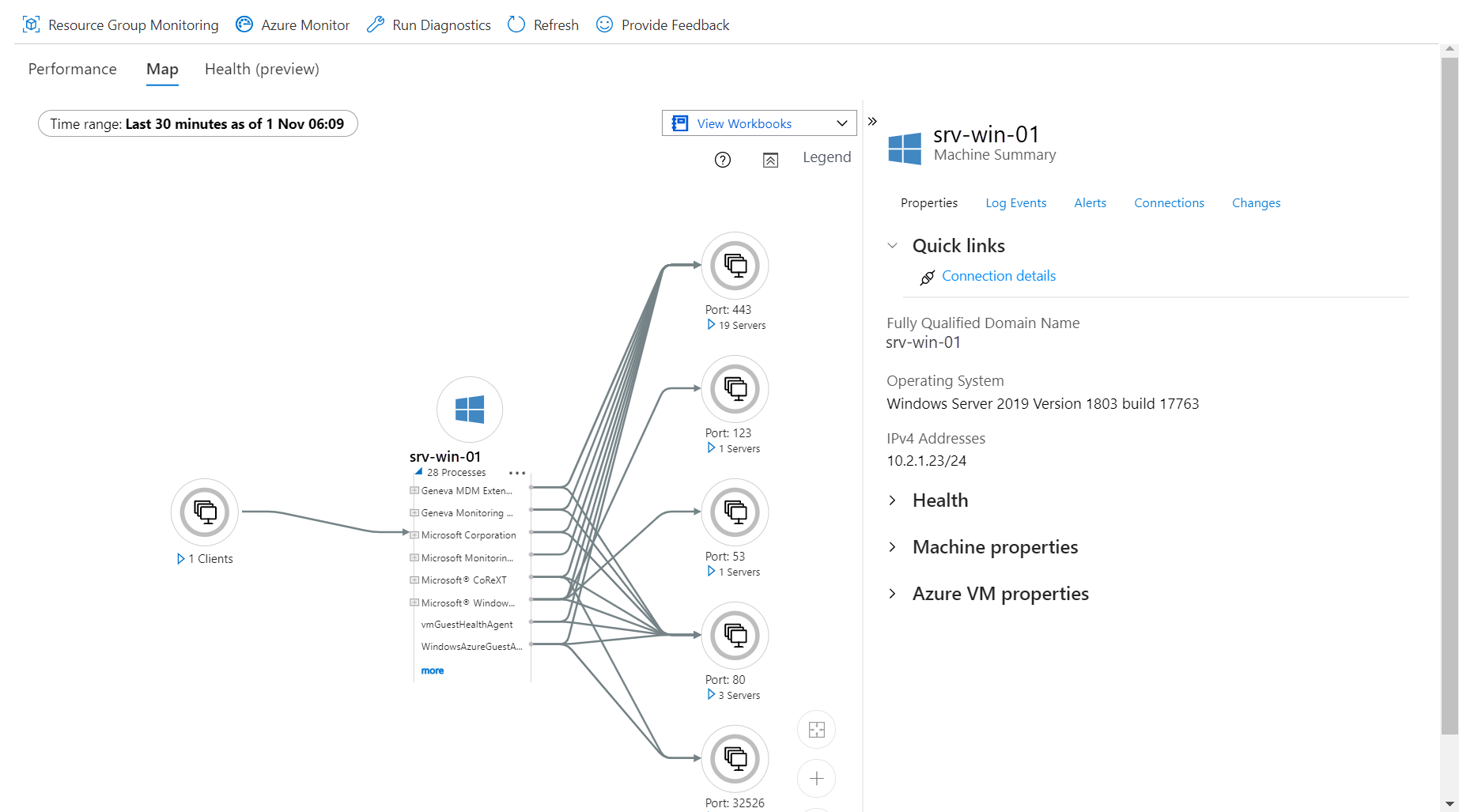
Hai mai passato ore davanti a una dashboard di monitoraggio cercando di capire perché il tuo database SQL sembrava improvvisamente bloccato nel traffico dell'ora di punta? Succede a tutti. Il problema è che spesso i dati sono troppi e mal organizzati. Se stai lavorando con l'ecosistema Microsoft, lo strumento App Inmsight Azure Find Sp Executuion diventa la tua bussola per individuare esattamente quali procedure memorizzate stanno rallentando il sistema. Non si tratta di guardare grafici colorati che non dicono nulla, ma di scavare nei log per estrarre la verità tecnica. In questo articolo ti spiego come configurare le query, cosa cercare tra le righe di codice e come evitare i soliti errori che fanno perdere tempo prezioso ai team di sviluppo.
Perché le procedure memorizzate sfuggono al controllo
Le procedure memorizzate sono comode. Incapsulano la logica, riducono il traffico di rete e possono essere ottimizzate direttamente sul server. Ma hanno un lato oscuro. Quando una di esse inizia a comportarsi male, magari a causa di un piano di esecuzione scaduto o di un parametro particolare che causa un parameter sniffing, trovarla nel mucchio non è immediato. Spesso ci si accorge del problema solo quando il consumo di CPU schizza al 90% o le richieste iniziano ad andare in timeout.
Molti sviluppatori si limitano a guardare le metriche aggregate. Sbagliato. Devi scendere nel dettaglio delle singole chiamate. Se non hai configurato correttamente la telemetria, vedrai solo un generico errore di connessione o una latenza elevata sulla dipendenza SQL. Questo non ti dice quale comando ha causato il rallentamento. Ti serve precisione chirurgica.
Il ruolo dei log di tracciamento
Il tracciamento delle dipendenze cattura il nome del comando inviato al database. Questo è il punto di partenza. Senza queste informazioni, sei cieco. Devi assicurarti che il driver che usi, sia esso .NET, Java o Python, passi correttamente i metadati alla piattaforma di analisi. Ho visto troppe volte configurazioni dove il comando SQL veniva troncato o oscurato per motivi di privacy eccessivi, rendendo il monitoraggio del tutto inutile.
La latenza non è l'unico nemico
C'è anche la questione della frequenza. Una procedura che impiega solo 200 millisecondi può sembrare innocua. Ma se viene chiamata 50.000 volte al minuto, l'impatto complessivo sul database è devastante. Devi bilanciare l'analisi tra il tempo di esecuzione singolo e il volume totale delle chiamate. Solo così avrai un quadro chiaro della situazione.
Configurare App Inmsight Azure Find Sp Executuion per l'analisi
Per ottenere risultati reali, devi sporcarti le mani con il linguaggio Kusto (KQL). Non basta cliccare sui bottoni predefiniti del portale. La potenza di questo sistema risiede nella possibilità di interrogare i log in modo granulare. Una query ben scritta può isolare le chiamate alle procedure in pochi secondi.
Supponiamo che tu voglia vedere le prime dieci procedure più lente dell'ultima ora. Dovrai filtrare la tabella delle dipendenze cercando specificamente i tipi legati a SQL. Molti dimenticano di escludere le chiamate fallite in questa fase, ma io ti consiglio di tenerle. A volte una procedura è lenta proprio perché sta tentando di gestire un errore interno o un blocco che poi sfocia in un fallimento.
Filtrare per tipo di comando
Il segreto sta nel filtrare la colonna dei dati. Le procedure memorizzate solitamente iniziano con un comando specifico o vengono chiamate tramite il loro nome preceduto da "EXEC". Usando gli operatori di stringa in KQL, puoi isolare questi schemi. È qui che la maggior parte delle persone sbaglia: usano filtri troppo larghi e finiscono per analizzare anche le query ad-hoc inviate dall'applicazione, confondendo i risultati.
Gestire i parametri dinamici
Un altro ostacolo è rappresentato dai parametri. Se la tua applicazione invia stringhe SQL diverse per ogni chiamata, la telemetria le vedrà come operazioni separate. Devi imparare a normalizzare questi dati. L'obiettivo è raggruppare tutte le esecuzioni della stessa procedura, indipendentemente dai valori passati, per calcolare una media attendibile delle prestazioni.
Ottimizzazione delle prestazioni reali sul campo
Una volta identificata la procedura problematica, il lavoro non è finito. Inizia la fase di ottimizzazione. Ho gestito sistemi dove una singola modifica a un indice ha ridotto il carico del server del 40%. Ma prima di toccare il database, devi capire cosa sta succedendo dentro quella procedura.
Usa i dati raccolti per replicare l'ambiente di errore. Se la telemetria ti dice che la procedura rallenta solo in certi orari, controlla se ci sono processi in background, come backup o ricostruzione di indici, che interferiscono. Spesso il colpevole non è il codice della procedura stessa, ma l'ambiente in cui gira.
L'importanza dei piani di esecuzione
Il piano di esecuzione è la mappa che il database segue per recuperare i dati. Se questa mappa è vecchia o sbagliata, il database farà giri immensi per nulla. Puoi recuperare i piani direttamente da Azure SQL Database usando le viste di gestione dinamica. Incrociare questi dati con quelli della telemetria applicativa ti dà una visione a 360 gradi che nessun altro strumento può offrirti.
Errori comuni nella lettura dei log
Un errore che vedo fare spesso è ignorare la colonna della durata perché si pensa che includa il tempo di rete. In realtà, la telemetria delle dipendenze misura il tempo dal momento in cui la richiesta lascia l'app al momento in cui torna la risposta. Se la latenza di rete tra l'app e il database è bassa, quel numero rappresenta quasi interamente il tempo di esecuzione sul server. Non cercare scuse nella rete se il database è lento.
Strategie avanzate per team di sviluppo
Se lavori in un team grande, non puoi essere l'unico a saper leggere questi dati. Devi creare una cultura del monitoraggio. Questo significa impostare avvisi automatici che scattano quando una specifica procedura supera una soglia critica. Non aspettare che l'utente segnali il rallentamento.
Creare dashboard personalizzate
Le dashboard sono utili solo se mostrano ciò che conta. Crea una vista dedicata esclusivamente alle procedure critiche. Includi grafici sulla durata media, sul numero di chiamate e sulla percentuale di errori. Se vedi un picco improvviso nel numero di esecuzioni, probabilmente c'è un bug nel codice dell'applicazione che sta chiamando il database più del dovuto, magari all'interno di un ciclo che poteva essere ottimizzato.
Analisi delle tendenze a lungo termine
Non guardare solo all'ultima ora. Confronta le prestazioni di oggi con quelle della settimana scorsa. Questo ti aiuta a identificare il degrado progressivo delle prestazioni, tipico dei database che crescono in volume senza che gli indici vengano aggiornati. È un lavoro di monitoraggio costante, quasi come curare un giardino.
Risoluzione dei problemi di connettività e timeout
Quando una procedura memorizzata va in timeout, l'applicazione riceve un'eccezione. Ma cosa vede la telemetria? Spesso vedrai una dipendenza fallita con un codice di errore specifico. È vitale mappare questi codici. Un errore di timeout (solitamente il numero 2) indica che il server ha impiegato troppo tempo, mentre un errore di connessione indica problemi di rete o di autenticazione.
Sapere come distinguere questi due casi ti risparmia ore di debug inutile. Se è un timeout, concentrati sulla query. Se è un errore di rete, controlla i firewall, i gruppi di sicurezza di rete e i limiti di connessione del tuo piano Azure. Ricorda che anche i database più potenti hanno dei limiti di sessioni contemporanee.
Gestire i picchi di carico
Durante i picchi di carico, come un evento di vendita o un lancio di un prodotto, le procedure che solitamente vanno bene possono cedere. In questi scenari, l'uso di App Inmsight Azure Find Sp Executuion è fondamentale per decidere se scalare verticalmente il database o se è necessario un intervento d'urgenza sul codice. A volte, disabilitare temporaneamente una funzionalità non critica che pesa sul database può salvare l'intero sistema dal crash totale.
Utilizzo delle risorse e costi
Non dimenticare l'aspetto economico. Ogni secondo di CPU su Azure ha un costo. Ottimizzare una procedura memorizzata non serve solo a rendere felici gli utenti, ma serve anche a ridurre la bolletta mensile. Un database che lavora meno permette di scendere di livello di servizio (SKU), risparmiando migliaia di euro all'anno su infrastrutture di grandi dimensioni.
Passi pratici per implementare un monitoraggio efficace
Ora che abbiamo visto la teoria e la strategia, passiamo all'azione. Non serve fare tutto subito, puoi procedere per gradi. L'importante è iniziare a raccogliere i dati corretti.
- Verifica la configurazione del tuo SDK di telemetria. Assicurati che la raccolta delle dipendenze SQL sia attiva e che non stia mascherando i nomi dei comandi. Se usi .NET, controlla il file di configurazione o il codice di inizializzazione dei servizi.
- Accedi alla console di query dei log. Inizia a scrivere piccole query KQL per elencare le dipendenze di tipo SQL. Cerca di capire come vengono registrate le tue procedure memorizzate. Appaiono come "EXEC nome_procedura" o in un altro formato?
- Crea un alert di base. Imposta una soglia di durata che ritieni inaccettabile per le tue operazioni più critiche. Ricevere una mail quando una procedura impiega più di 5 secondi è il primo passo verso un monitoraggio proattivo.
- Controlla la documentazione ufficiale di Microsoft Azure per restare aggiornato sulle nuove funzionalità di analisi dei log. Gli strumenti cambiano velocemente e spesso vengono rilasciate nuove funzioni KQL che semplificano il raggruppamento e l'analisi statistica dei dati.
- Esamina periodicamente i report sulle prestazioni. Una volta alla settimana, dedica trenta minuti ad analizzare quali sono le procedure che consumano più risorse. Non focalizzarti solo sulle più lente, ma anche su quelle più frequenti.
- Collabora con i DBA (Database Administrator). Condividi con loro i dati estratti dalla telemetria applicativa. Spesso loro hanno una visuale dal lato server, ma gli manca il contesto dell'applicazione. Unire queste due visioni è la chiave per risolvere i problemi più complessi.
Gestire le prestazioni di un database in cloud richiede un approccio diverso rispetto ai server locali. Gli strumenti ci sono, ma vanno usati con criterio. Non lasciare che i tuoi dati affoghino nel rumore di fondo dei log. Isola ciò che conta, misura con precisione e agisci dove l'impatto è maggiore. La telemetria non è solo un costo o un requisito di conformità, è lo strumento principale per garantire che la tua applicazione rimanga veloce, affidabile e scalabile nel tempo. Onestamente, una volta che inizi a vedere esattamente cosa succede nel tuo database in tempo reale, non potrai più tornare indietro al vecchio metodo basato sulle supposizioni e sui tentativi alla cieca.



