Ho visto questa scena ripetersi troppe volte per contarle. Un team di sviluppo lancia una nuova funzionalità, tutto sembra girare alla perfezione sui loro computer portatili e persino nell’ambiente di test dove ci sono solo poche migliaia di righe. Il comando Create Table With SQL Query viene eseguito in pochi millisecondi, le tabelle sono pronte e il codice viene distribuito in produzione. Poi, circa sei mesi dopo, arriva la telefonata alle tre del mattino. Il database è piantato, le transazioni vanno in timeout e la CPU del server è fissa al 99%. Il problema non è il traffico improvviso, ma una struttura dati progettata con superficialità che ha accumulato debiti tecnici fino a diventare insostenibile. Spendere soldi in hardware più potente per coprire errori di design è come cercare di riempire un secchio bucato con una pompa più grande.
Il mito del tipo di dato universale che divora la memoria
Uno dei fallimenti più costosi che incontro riguarda la scelta pigra dei tipi di dato. Molti sviluppatori alle prime armi pensano che usare un tipo di dato "abbondante" sia una forma di prevenzione, ma è l'esatto contrario. Ho lavorato con un'azienda di logistica che aveva definito tutte le colonne di testo come tipi a lunghezza variabile massimizzata e tutti i numeri come interi a 64 bit, anche per valori che non avrebbero mai superato il numero cento.
Quando definisci una colonna in questo modo, non stai solo occupando spazio su disco. Stai appesantendo la memoria RAM durante ogni operazione di ordinamento o join. Se il motore del database deve allocare memoria per una riga che sulla carta potrebbe essere enorme, anche se i dati reali sono piccoli, finirai per saturare il pool di buffer molto prima del previsto. In un caso reale, passare da un tipo di dato generico a uno calibrato ha ridotto l'occupazione di memoria del 40%, permettendo al server di mantenere l'intero indice in RAM invece di dover leggere continuamente dal disco, che è ordini di grandezza più lento.
Non si tratta di essere pignoli. Si tratta di capire come il database organizza le pagine di memoria. Se le tue righe sono inutilmente larghe, meno righe entrano in una singola pagina dati. Questo significa più operazioni di input/output per ogni singola scansione. La soluzione pratica è guardare i tuoi dati reali. Se una colonna ospiterà solo codici di stato di due lettere, usa un tipo a lunghezza fissa di due caratteri. Se un numero non sarà mai negativo e non supererà 255, usa il tipo di dato intero più piccolo disponibile. Risparmiare byte oggi significa salvare la stabilità del sistema domani.
Dimenticare i vincoli di integrità nella Create Table With SQL Query
Un altro errore sistematico è delegare tutta la logica di validazione al codice applicativo, lasciando lo schema del database "aperto" a ogni tipo di immondizia. Ho visto database pieni di record orfani, date impossibili come il 31 febbraio e stringhe vuote dove dovrebbero esserci identificativi vitali. La scusa è sempre la stessa: "La validazione la facciamo nel backend, così il database è più veloce".
Questa è una bugia pericolosa. Prima o poi, qualcuno eseguirà uno script manuale per correggere un bug, o un altro servizio si collegherà direttamente alla base dati saltando i controlli del tuo backend. In quel momento, l'integrità dei tuoi dati morirà. Usare correttamente le chiavi esterne, i vincoli di non nullità e i controlli di validità direttamente nello schema non è un optional burocratico. È l'ultima linea di difesa del tuo capitale aziendale: i dati stessi.
L'impatto economico di un dato sporco è immenso. Ore di lavoro perse dai data analyst per pulire i report, decisioni di business prese su numeri sbagliati e crash improvvisi dell'applicazione che non sa come gestire un valore nullo inaspettato. Inserire questi vincoli nel momento in cui si scrive il codice per la creazione delle strutture costa pochi minuti. Recuperare la coerenza di un database da terabyte con dati corrotti può richiedere settimane di downtime e consulenze esterne da migliaia di euro.
L'illusione degli indici su ogni colonna
Esiste una tendenza opposta, altrettanto dannosa: indicizzare tutto per paura che le query siano lente. Ho analizzato un sistema di e-commerce dove ogni singola colonna della tabella ordini aveva il proprio indice dedicato. Pensavano di aver coperto ogni possibile scenario di ricerca, ma avevano creato un mostro immobile. Ogni volta che veniva inserito un nuovo ordine, il database doveva aggiornare quindici indici diversi.
Le prestazioni in scrittura erano crollate e i blocchi sulle tabelle erano diventati la norma. Gli indici sono come i libri in una biblioteca: aiutano a trovare le informazioni, ma occupano spazio e richiedono lavoro per essere mantenuti aggiornati. Un indice non utilizzato è puro spreco di risorse. La strategia corretta non è quella di sparare nel mucchio, ma di analizzare i pattern di accesso. Spesso un unico indice composto su due o tre colonne è dieci volte più efficace di tre indici separati, perché permette al motore di trovare esattamente ciò che serve senza saltare da una struttura all'altra.
Dalla mia esperienza, l'approccio vincente è partire con il minimo indispensabile — chiavi primarie e chiavi esterne — e aggiungere indici solo dopo aver osservato il piano di esecuzione delle query reali sotto carico. Non puoi prevedere con esattezza come l'ottimizzatore del database si comporterà finché non hai dati veri e volumi significativi.
Progettare per oggi ignorando la crescita futura
Consideriamo uno scenario reale di una startup che si occupa di sensori IoT. All'inizio, hanno creato una tabella dove ogni riga conteneva i dati di un sensore per ogni minuto. Hanno usato un identificativo incrementale standard a 32 bit. Sembrava una scelta ragionevole.
- Approccio sbagliato: Usare un intero a 32 bit per la chiave primaria in una tabella ad alta frequenza di inserimento. Dopo circa due anni, il sistema raggiunge il limite massimo di circa 2,1 miliardi di righe. All'improvviso, il database smette di accettare nuovi dati. L'azienda deve fermare tutto, migrare miliardi di righe in una nuova struttura con chiavi a 64 bit, con un costo di downtime stimato in decine di migliaia di euro di mancati contratti di servizio.
- Approccio giusto: Prevedere il volume di dati basandosi sulle proiezioni di crescita. Se sai che riceverai migliaia di inserimenti al secondo, parti subito con chiavi a 64 bit o sistemi di partizionamento. Anche se occupa leggermente più spazio, eviti il muro invalicabile del limite tecnico che si presenterà inevitabilmente nel momento peggiore possibile.
Questa differenza di prospettiva separa i professionisti dai dilettanti. Non si tratta di complicare il design, ma di scegliere lo strumento adatto alla scala del problema. Se sai che la tabella crescerà oltre i limiti gestibili in un unico file, devi considerare il partizionamento fin dal primo giorno. Spostare una tabella viva da una struttura piatta a una partizionata è un intervento chirurgico a cuore aperto che nessuno vuole fare.
L'errore del fuso orario locale e la trappola del testo
Non c'è niente che faccia perdere tempo quanto dover correggere i dati temporali dopo un cambio di ora legale o dopo aver acquisito un cliente in un fuso orario diverso. Molti database vengono configurati usando l'ora locale del server. È una ricetta per il disastro. Ho visto report finanziari sballati perché le transazioni avvenute tra le 02:00 e le 03:00 del mattino nel giorno del cambio ora venivano contate due volte o sparivano nel nulla.
La regola d'oro è semplice: memorizza sempre le date e gli orari in formato UTC. La conversione per l'utente finale deve avvenire solo a livello di interfaccia. Allo stesso modo, la gestione delle codifiche dei caratteri viene spesso sottovalutata. Usare una codifica limitata per risparmiare qualche bit significa che il giorno in cui un cliente inserisce un nome con un carattere speciale o un'emoji, l'intero inserimento fallirà o, peggio, i dati verranno salvati come simboli incomprensibili. Nel 2026, non c'è motivo per non utilizzare lo standard UTF-8 completo fin dall'inizio.
La gestione dei valori nulli e la logica a tre valori
Molti sottovalutano la complessità che i valori nulli introducono nelle query. In SQL, NULL non significa zero o stringa vuota; significa "informazione sconosciuta". Questo porta alla cosiddetta logica a tre valori (Vero, Falso, Sconosciuto), che è la fonte primaria di bug logici nelle estrazioni dati.
Ho visto programmatori esperti sbagliare query di reportistica perché avevano dimenticato che VALORE <> 10 non restituisce le righe dove VALORE è NULL. Se una colonna può non avere un dato, devi essere pronto a gestire questa incertezza in ogni singola query futura. Se invece puoi stabilire un valore di default sensato, fallo. Rendere le colonne obbligatorie (NOT NULL) semplifica enormemente la scrittura del codice e permette all'ottimizzatore di fare un lavoro migliore. Non è solo una questione di pulizia, è una questione di prevedibilità dei risultati.
Ecco alcuni punti fermi da verificare prima di premere invio su un comando di creazione:
- Verifica che ogni colonna abbia il tipo di dato più piccolo possibile per il suo scopo.
- Assicurati che i nomi delle tabelle e delle colonne seguano una convenzione coerente e non usino parole riservate.
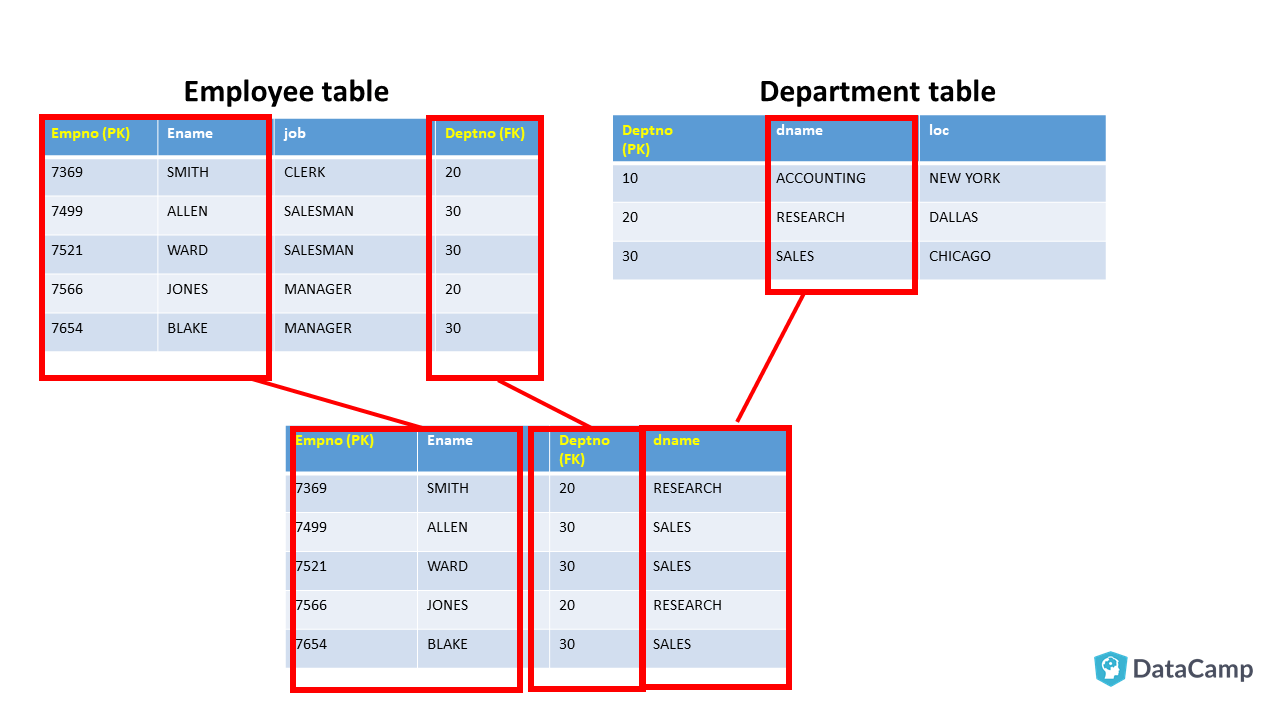
- Controlla che le chiavi esterne abbiano indici associati, altrimenti i join saranno un incubo.
- Definisci esplicitamente il set di caratteri e la collation per evitare comportamenti diversi tra server di sviluppo e produzione.
- Documenta il motivo per cui certe scelte sono state fatte direttamente nel codice dello schema.
La realtà brutale della gestione dei database
Siamo onesti: non esiste la struttura perfetta che durerà per sempre. Il business cambia, le esigenze evolvono e quello che oggi sembra un ottimo design tra due anni potrebbe essere un collo di bottiglia. Tuttavia, c'è una differenza abissale tra un sistema che deve essere aggiornato e uno che crolla sotto il suo stesso peso per errori evitabili.
Il successo con la Create Table With SQL Query non deriva dalla conoscenza a memoria della sintassi, ma dalla comprensione di come i dati vivono sul disco e nella memoria. Non farti incantare dalle mode del momento o dalla pigrizia di chi dice che "tanto il database gestisce tutto da solo". Il database è un software, segue le regole della fisica e della logica. Se gli dai istruzioni mediocri, otterrai prestazioni mediocri.
La verità è che la maggior parte dei problemi di scalabilità che le aziende attribuiscono al database sono in realtà problemi di design dello schema. Se non capisci come il tuo motore database indicizza, memorizza e recupera le informazioni, sei solo un passeggero su un treno che non controlli. Imparare a progettare bene le tabelle non è l'attività più eccitante del mondo, ma è quella che ti permetterà di dormire la notte mentre i sistemi degli altri bruciano. Non cercare scorciatoie; non esistono. Esiste solo la pianificazione rigorosa e l'attenzione ai dettagli che nessuno vede finché non si rompono.



