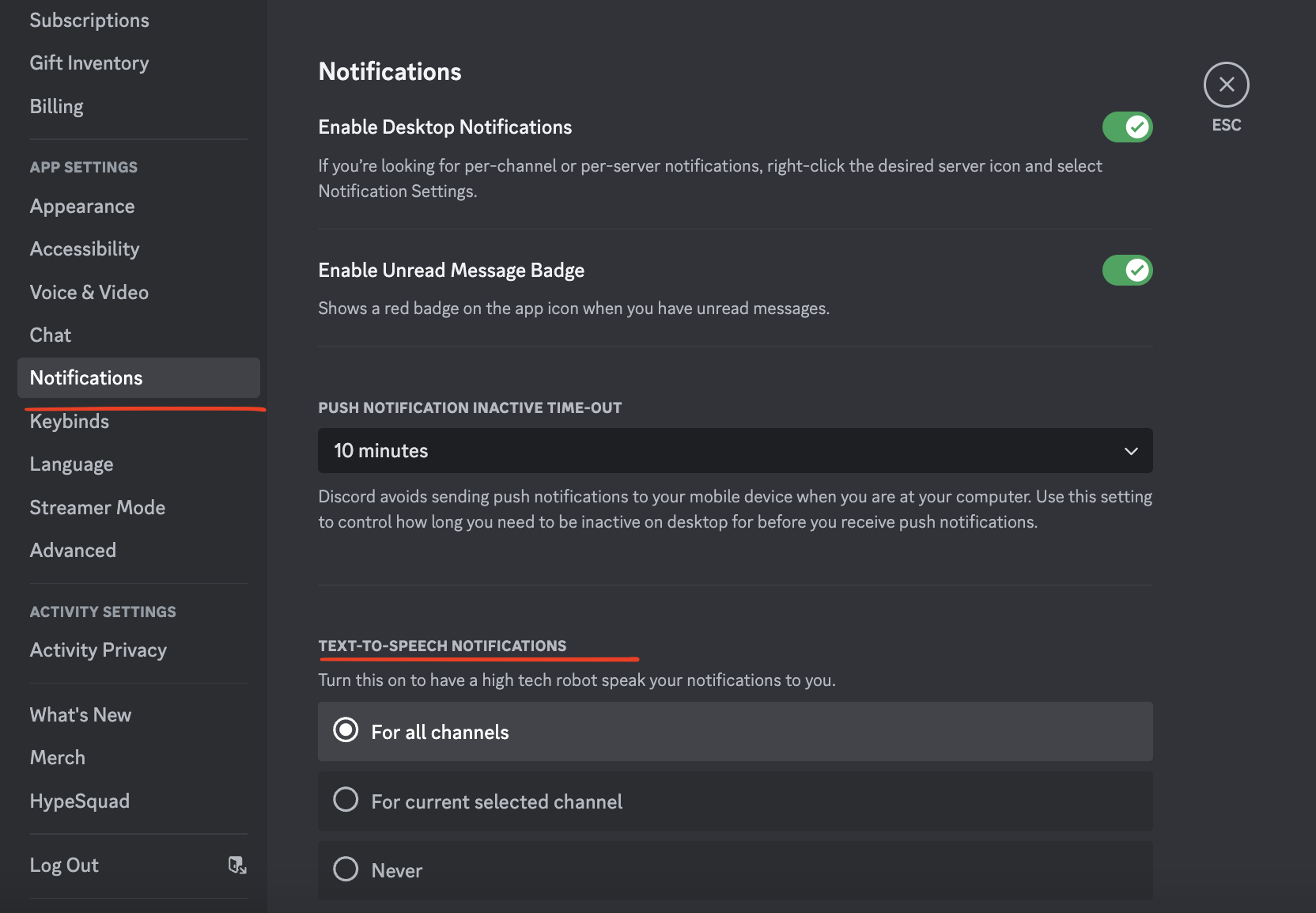
L'integrazione di sistemi avanzati di sintesi vocale ha registrato un incremento nell'adozione da parte delle comunità online globali durante il primo trimestre del 2026. L'implementazione di un Discord Text To Speech Bot permette la conversione istantanea dei messaggi scritti in flussi audio all'interno dei canali vocali, facilitando la partecipazione degli utenti con disabilità visive o motorie. Secondo i dati pubblicati nel rapporto annuale di Discord sulla trasparenza, l'uso di strumenti di assistenza vocale è aumentato del 22% rispetto all'anno precedente.
Questa tecnologia si basa su algoritmi di elaborazione del linguaggio naturale che analizzano il testo in tempo reale per riprodurre una voce sintetica con intonazione umana. Stanislav Vishnevskiy, co-fondatore di Discord, ha confermato in una nota ufficiale che l'azienda punta a migliorare l'inclusività attraverso il potenziamento delle API dedicate alla voce. Le comunità di videogiocatori e i server educativi rappresentano i segmenti di utenza che utilizzano maggiormente queste funzionalità per gestire sessioni di apprendimento o coordinamento tattico senza la necessità di guardare costantemente lo schermo.
Lo sviluppo di tali sistemi avviene attraverso protocolli di programmazione che collegano i server della piattaforma a motori di sintesi esterni o interni. I ricercatori del W3C Web Accessibility Initiative indicano che la standardizzazione di queste interfacce è un passo necessario per garantire che nessun utente venga escluso dalle interazioni sociali digitali. Il processo di installazione richiede solitamente l'autorizzazione di permessi specifici all'interno del server, consentendo al software di leggere il contenuto delle chat testuali e trasmetterlo sotto forma di segnale audio.
Evoluzione tecnica del Discord Text To Speech Bot
Il passaggio dai primi sistemi rudimentali a modelli basati su reti neurali ha trasformato radicalmente la qualità della riproduzione vocale. I vecchi motori di sintesi producevano suoni metallici e privi di modulazione, mentre le versioni attuali utilizzano il deep learning per imitare le pause e le variazioni di tono tipiche del parlato umano. Un report tecnico di Microsoft Azure AI evidenzia come la latenza nella conversione da testo a voce sia scesa sotto i 200 millisecondi, rendendo la conversazione fluida e naturale.
L'architettura di questi bot si appoggia spesso a servizi cloud che offrono librerie linguistiche multilingue estremamente vaste. Questo permette agli amministratori dei server di configurare voci differenti in base alla lingua predominante della propria comunità, supportando oltre 40 idiomi diversi. Gli sviluppatori indipendenti caricano regolarmente nuove versioni di questi strumenti su repository pubblici come GitHub, contribuendo a una rapida diffusione di soluzioni personalizzate.
L'ottimizzazione del codice ha permesso di ridurre il consumo di risorse computazionali sui dispositivi degli utenti finali. Mentre in precedenza l'esecuzione di processi vocali pesanti poteva rallentare le prestazioni del sistema, oggi la maggior parte del carico di lavoro viene gestita lato server o tramite API leggere. Questa efficienza garantisce che anche gli utenti con hardware meno recente possano beneficiare delle funzionalità audio senza riscontrare cali di frame rate durante l'esecuzione di altre applicazioni.
Sfide legate alla privacy e alla moderazione dei contenuti
La capacità di un software di leggere ad alta voce ogni messaggio inserito in una chat solleva questioni rilevanti riguardanti la sicurezza e la gestione delle molestie. Molti server hanno segnalato casi di utilizzo improprio della sintesi vocale per aggirare i filtri testuali di moderazione, utilizzando fonemi che riproducono parole vietate. I dati diffusi da CyberBullying Research Center suggeriscono che l'automazione vocale richieda nuovi protocolli di controllo per evitare che diventi uno strumento di disturbo.
Gli amministratori di sistema dispongono ora di strumenti per limitare l'accesso alla funzione solo a ruoli specifici o canali dedicati. Questa gerarchia di permessi è fondamentale per prevenire il fenomeno dello spam acustico, dove utenti malintenzionati inondano i canali vocali con messaggi ripetitivi. La configurazione corretta del Discord Text To Speech Bot include spesso filtri anti-spam che bloccano la lettura di messaggi eccessivamente lunghi o contenenti sequenze di caratteri senza senso.
Le preoccupazioni riguardanti la privacy dei dati rimangono al centro del dibattito tra gli attivisti per i diritti digitali. Poiché i messaggi devono essere inviati a un server di elaborazione per la sintesi vocale, esiste il rischio teorico che le conversazioni vengano tracciate o memorizzate da terze parti. L'organizzazione Electronic Frontier Foundation ha spesso sottolineato l'importanza della crittografia end-to-end anche per i metadati associati a questi servizi di automazione.
Impatto economico e mercato degli sviluppatori indipendenti
Il settore dei servizi per le piattaforme di comunicazione ha generato un ecosistema economico dove gli sviluppatori possono monetizzare versioni premium dei propri software. Molti bot offrono una versione base gratuita, mentre le funzionalità avanzate come voci di alta qualità o traduzione simultanea richiedono un abbonamento mensile. Secondo una stima di Business Insider, il mercato degli add-on per le piattaforme social è cresciuto del 15% nell'ultimo biennio, attirando investimenti da parte di venture capital.
Le aziende di tecnologia vocale stanno stringendo partnership con i creatori di contenuti per offrire esperienze sonore uniche. In alcuni casi, celebrità o doppiatori professionisti prestano la propria voce per essere utilizzata dai sistemi di sintesi all'interno dei server più popolari. Questa commercializzazione ha trasformato un semplice strumento di accessibilità in una fonte di intrattenimento e personalizzazione per milioni di utenti.
Le piccole startup di sviluppo software trovano in queste piattaforme un terreno fertile per testare nuovi algoritmi di intelligenza artificiale. L'assenza di barriere all'entrata elevate permette a singoli programmatori di competere con grandi aziende offrendo soluzioni più agili e vicine alle esigenze specifiche delle nicchie di utenti. Molti di questi progetti vengono sostenuti attraverso campagne di crowdfunding, dimostrando un forte legame tra la base di utenti e i produttori di tecnologia.
Integrazione tra intelligenza artificiale e sintesi vocale
L'ultima frontiera dello sviluppo riguarda l'integrazione di modelli linguistici di grandi dimensioni con i sistemi di riproduzione audio. Questa sinergia permette ai bot non solo di leggere il testo, ma di comprenderne il contesto e di adattare l'enfasi vocale di conseguenza. Se un utente scrive una frase che denota urgenza o felicità, il sistema è in grado di modificare il tono della voce sintetica per riflettere lo stato emotivo sottostante.
I ricercatori del settore sostengono che questa evoluzione riduca il carico cognitivo necessario per interpretare le interazioni digitali. Uno studio condotto dalla Stanford University ha rilevato che gli utenti preferiscono interagire con voci sintetiche che mostrano una minima variazione prosodica rispetto a voci piatte e monotone. L'obiettivo a lungo termine è eliminare completamente la distinzione percepita tra una voce registrata e una generata sinteticamente in tempo reale.
Tuttavia, l'aumento della complessità tecnologica comporta una maggiore necessità di potenza di calcolo e connessioni internet stabili. Gli sviluppatori stanno lavorando su modelli di compressione che consentano di mantenere un'elevata fedeltà audio anche in condizioni di larghezza di banda limitata. Questo sforzo tecnico è fondamentale per garantire che le popolazioni con accesso limitato alle infrastrutture digitali non rimangano indietro in questa transizione verso una comunicazione più sonora.
Personalizzazione e identità vocale digitale
All'interno delle comunità virtuali, la scelta di una specifica voce sintetica sta diventando una forma di espressione dell'identità digitale. Gli utenti possono selezionare timbri vocali che riflettono la propria personalità o l'avatar che utilizzano online. Questa tendenza è particolarmente evidente nei server dedicati al gioco di ruolo, dove la coerenza tra il personaggio e la sua voce è un elemento essenziale dell'esperienza immersiva.
Le interfacce di configurazione permettono di regolare parametri come la velocità di lettura, l'altezza del tono e il volume di uscita in modo indipendente per ogni utente. Questa granularità di controllo assicura che l'esperienza sia confortevole per chi soffre di ipoacusia o altre sensibilità uditive. La possibilità di salvare profili vocali personalizzati facilita il passaggio da un server all'altro mantenendo una coerenza sonora costante.
Requisiti infrastrutturali e compatibilità tra sistemi
L'adozione di massa di strumenti vocali automatici ha spinto le aziende di hosting a potenziare le proprie infrastrutture di rete. Il traffico dati generato dai flussi audio è significativamente superiore a quello dei semplici messaggi di testo, richiedendo server capaci di gestire picchi di carico simultanei. Le statistiche fornite da Cloudflare indicano che l'ottimizzazione delle rotte di rete è un fattore determinante per ridurre i fenomeni di jitter e perdita di pacchetti audio.
La compatibilità tra diversi sistemi operativi e dispositivi mobili rappresenta un'altra sfida tecnica rilevante. Gli sviluppatori devono garantire che il bot funzioni correttamente sia su applicazioni desktop che su versioni mobile, dove le restrizioni sui processi in background sono più severe. La maggior parte dei bot moderni viene eseguita come istanza web, facilitando l'interoperabilità tra diverse architetture hardware senza richiedere installazioni locali complesse.
Il supporto per le API di terze parti rimane un punto di forza per la diffusione di queste tecnologie. Consentire a software esterni di interagire con il flusso audio del server permette la creazione di ecosistemi di applicazioni che vanno oltre la semplice lettura del testo. Esempi di queste applicazioni includono sistemi di notifica automatica per eventi in tempo reale, come aggiornamenti meteo o notizie dell'ultima ora, trasmessi direttamente nei canali vocali.
Prospettive future per l'automazione vocale nelle piattaforme social
Il futuro della comunicazione digitale sembra orientato verso una fusione sempre più profonda tra testo e voce. Gli analisti di Gartner prevedono che entro la fine del 2027 oltre la metà delle interazioni sui social network avverrà tramite interfacce vocali assistite da intelligenza artificiale. Questo cambiamento di paradigma richiederà un costante aggiornamento delle politiche di utilizzo e dei sistemi di protezione degli utenti.
Le autorità di regolamentazione dell'Unione Europea stanno monitorando attentamente lo sviluppo di queste tecnologie per assicurare che rispettino le normative sulla protezione dei dati personali. Il dibattito legislativo si sta concentrando sulla trasparenza degli algoritmi e sull'obbligo di dichiarare quando una voce è sintetica per prevenire manipolazioni o frodi basate sul deepfake audio. La sicurezza informatica diventerà un elemento centrale nella progettazione delle prossime generazioni di software per la comunicazione.
La ricerca si sta ora concentrando sulla riduzione del consumo energetico dei data center che alimentano questi servizi globali. La sostenibilità ambientale delle infrastrutture digitali è una priorità per le grandi aziende tecnologiche, che cercano di ottimizzare gli algoritmi per richiedere meno cicli di calcolo. Il monitoraggio dell'impatto ecologico di milioni di processi di sintesi vocale eseguiti quotidianamente rimarrà un tema centrale nelle agende dei decisori politici e dei vertici industriali nei prossimi anni.



