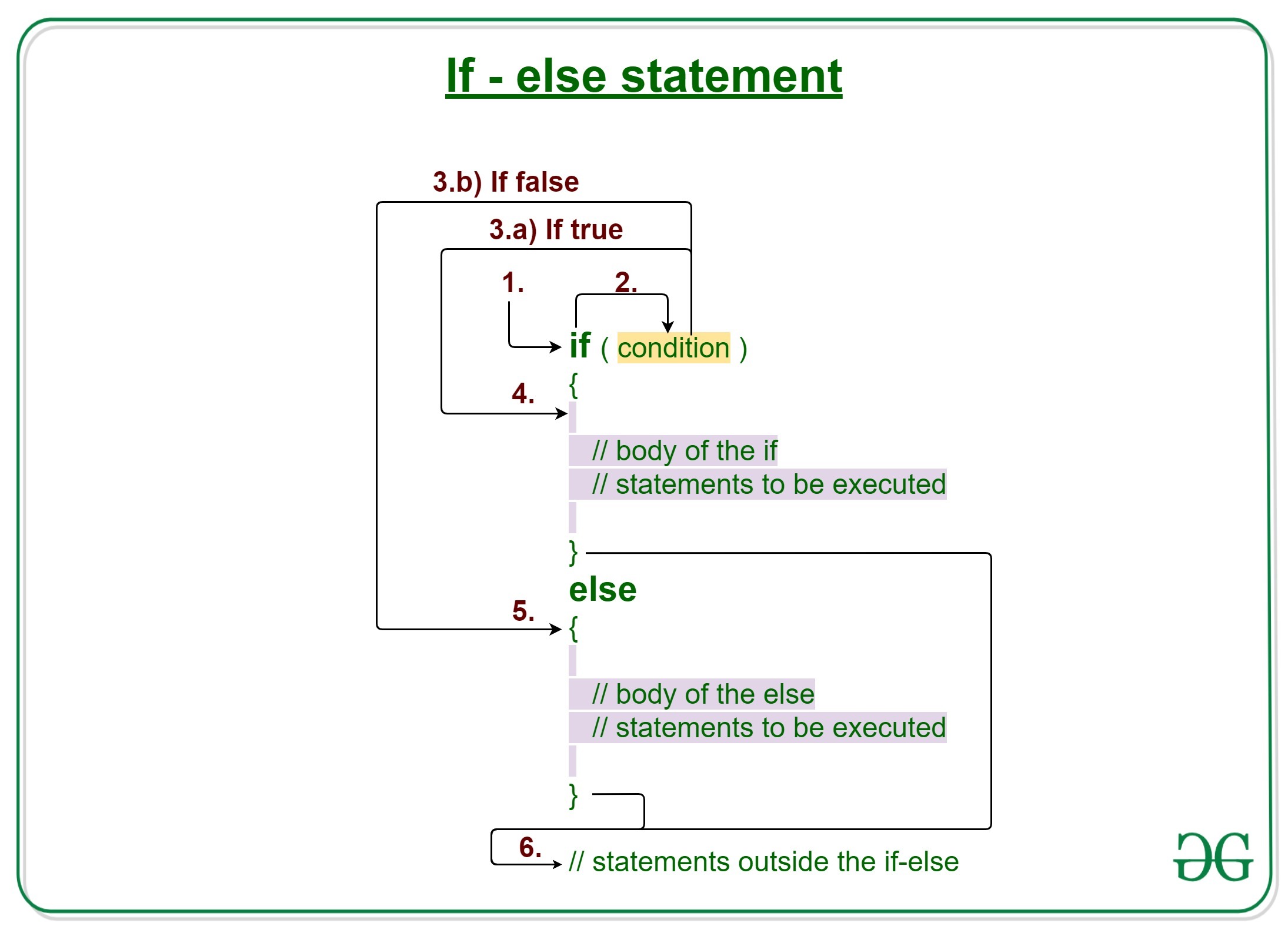
Ho visto decine di data scientist perdere intere notti di sonno e migliaia di euro in ore di calcolo cloud perché convinti che un lungo Else If Statement In R fosse la soluzione a ogni problema di logica condizionale. Ricordo un progetto specifico per una catena di distribuzione europea: il team aveva costruito un sistema di categorizzazione dei prezzi basato su una catena infinita di condizioni. Funzionava sui test, ma quando l'hanno lanciato sui dati reali — milioni di righe — il codice è diventato un buco nero di risorse. Quello che doveva richiedere dieci minuti ne richiedeva sei, bloccando i server di produzione e ritardando l'aggiornamento dei listini per un intero weekend di vendite. Il costo del downtime e della mancata ottimizzazione è stato calcolato in circa 15.000 euro, solo perché nessuno aveva spiegato loro che la logica sequenziale non scala come pensano.
Il mito della logica sequenziale infinita
Il primo errore che commetti è pensare che aggiungere un'altra condizione sia gratis. In R, ogni volta che scrivi una nuova clausola, stai costringendo l'interprete a valutare ogni singolo passaggio precedente prima di arrivare a quello che ti serve. Se hai una condizione che si verifica nel 90% dei casi, ma la metti in fondo alla tua catena, stai buttando via cicli di CPU per niente.
Ho visto script dove la condizione più frequente era posizionata dopo venti controlli inutili. Non è solo una questione di eleganza; è una questione di fisica del calcolo. Ogni controllo richiede un micro-ritardo che, moltiplicato per un dataset da dieci milioni di osservazioni, diventa un'eternità. La soluzione non è smettere di usare la logica, ma capire che l'ordine conta più della sintassi stessa. Se non metti le condizioni ad alta probabilità all'inizio, stai sabotando la tua stessa infrastruttura.
Quando Else If Statement In R diventa un debito tecnico insostenibile
Molti sviluppatori alle prime armi usano questa struttura perché sembra "naturale", simile al modo in cui parliamo. "Se succede questo, fai quello, altrimenti se succede quest'altro, fai quest'altro ancora". Ma la leggibilità svanisce non appena superi le tre o quattro condizioni. Ho analizzato script ereditati da banche d'affari dove la logica nidificata era profonda dieci livelli. Nessuno sapeva più cosa succedesse nel caso "else" finale.
Il debito tecnico non è un concetto astratto: è il tempo che impiegherai tra sei mesi a capire perché un cliente riceve uno sconto sbagliato. Quando la catena diventa troppo lunga, la probabilità di introdurre bug logici — dove due condizioni si sovrappongono parzialmente — tende al 100%. È un suicidio professionale scrivere codice che solo tu puoi capire oggi, e che nemmeno tu capirai tra un mese.
La trappola della valutazione scalare su vettori
R è un linguaggio vettorializzato per natura. Uno degli errori più costosi che puoi fare è provare a far girare un ciclo for che contiene al suo interno un controllo condizionale su un intero data frame. È il modo più veloce per trasformare una workstation da 4.000 euro in un costoso radiatore da ufficio. Se stai controllando ogni riga una per una, stai ignorando la potenza del motore che hai sotto il cofano.
L'illusione della precisione nei controlli di uguaglianza
C'è una verità tecnica che molti ignorano finché non si scontrano con un errore di calcolo finanziario: i numeri decimali non sono mai precisi come sembrano. Ho visto interi report di audit fallire perché qualcuno ha scritto una condizione del tipo if (x == 0.3). In R, come in molti altri linguaggi, $0.1 + 0.2$ non è esattamente uguale a $0.3$ a causa della rappresentazione floating-point.
Se la tua logica dipende da un'uguaglianza perfetta su numeri reali, fallirai. Sempre. La soluzione professionale è usare una tolleranza o funzioni dedicate come isTRUE(all.equal(x, y)). Ignorare questo dettaglio non ti rende solo un programmatore pigro, ti rende pericoloso per l'integrità dei dati della tua azienda. Un errore dello 0,0000001% può sembrare irrilevante, ma su un bilancio da cento milioni di euro, i conti non torneranno mai e passerai giorni a cercare un fantasma nel codice.
Perché dovresti smettere di usare Else If Statement In R per le ricodifiche
Se il tuo obiettivo è trasformare una variabile categorica in un'altra, usare una struttura condizionale classica è un errore tattico. Immagina di dover mappare 50 codici regionali italiani ai rispettivi uffici di competenza. Se scrivi cinquanta clausole condizionali, stai creando un incubo di manutenzione.
L'approccio corretto non è scrivere più codice, ma usare strutture dati. Un semplice vettore nominato o un join con una tabella di riferimento trasforma cinquanta blocchi di codice in una singola riga di comando. Ho visto processi di pulizia dati passare da due ore di esecuzione a tre secondi semplicemente eliminando i controlli sequenziali a favore di una ricerca indicizzata. Non stai venendo pagato per scrivere mille righe di codice, ma per risolvere problemi nel minor tempo possibile.
Confronto pratico tra approccio ingenuo e professionale
Per capire davvero la differenza, guarda come cambia la gestione di un problema comune come la classificazione dei rischi di credito.
Un analista inesperto scriverebbe una sequenza che controlla se il punteggio è sotto 500, poi se è tra 500 e 600, poi tra 600 e 700, e così via. Ogni riga di dati deve passare attraverso ogni "porta" finché non trova quella giusta. Se il file ha un milione di posizioni, il computer esegue milioni di test logici ridondanti. Il codice appare lungo, difficile da testare e propenso a buchi (cosa succede se il punteggio è esattamente 600.0001?).
L'esperto, invece, usa la funzione findInterval o cut. Definisce i limiti una volta sola e lascia che R trovi la collocazione di ogni dato istantaneamente grazie ad algoritmi di ricerca binaria ottimizzati in C++. Il risultato è lo stesso, ma il secondo metodo è 50 volte più veloce, non permette sovrapposizioni logiche ed è leggibile in una riga. Nel mondo reale, questa differenza separa chi consegna il report alle 17:00 e va a casa da chi rimane in ufficio fino alle 22:00 a cercare di capire perché il codice si è piantato.
Il fallimento silenzioso del ramo finale
L'errore più subdolo che ho visto distruggere database di produzione è l'uso errato dell'ultimo else. Spesso viene usato come un cestino per "tutto il resto". Ma "tutto il resto" include anche i dati mancanti (NA), gli errori di input e i valori fuori scala che non avevi previsto.
Se non gestisci esplicitamente i valori NA prima di entrare nella tua logica condizionale, R si fermerà con un errore o, peggio, produrrà un risultato inaspettato che inquina le tue analisi successive. Ho visto modelli predittivi fornire risultati completamente distorti perché migliaia di record con dati mancanti erano finiti silenziosamente nella categoria "Rischio Basso" solo perché quella era l'ultima opzione della catena condizionale. La gestione degli errori non è un optional, è la parte più importante del lavoro.
Controllo della realtà sulla programmazione in R
Smettila di cercare la "soluzione elegante" e inizia a cercare quella che non si rompe sotto pressione. La verità è che se ti ritrovi a scrivere più di tre o quattro clausole condizionali annidate, hai già perso. Non importa quanto sei bravo a formattare il codice; la tua strategia di base è sbagliata.
R non è Python e non è C++. È un linguaggio nato per la statistica e la manipolazione di vettori. Se cerchi di forzarlo a comportarsi come un linguaggio procedurale classico, otterrai prestazioni mediocri e codice fragile. Per avere successo davvero non devi imparare a scrivere meglio le tue condizioni, ma devi imparare a evitarle del tutto usando la vettorializzazione, le tabelle di lookup e le funzioni della famiglia apply o del pacchetto dplyr.
La programmazione professionale non è mostrare quanto sei bravo a gestire la complessità, ma mostrare quanto sei stato capace di eliminarla. Se il tuo script è un labirinto di controlli incrociati, non sei un esperto: sei una vittima della tua stessa logica. Il giorno in cui inizierai a vedere ogni condizione come un potenziale punto di rottura anziché come uno strumento di controllo, inizierai a scrivere codice che produce valore invece di grattacapi. Non c'è gloria nel debuggare un errore che poteva essere evitato con una struttura dati migliore. La tua competenza si misura dalla velocità con cui il tuo codice gira e dalla facilità con cui un tuo collega può modificarlo senza chiamarti nel cuore della notte.



