Immagina di essere a metà di un rilascio critico per un cliente che non accetta ritardi. Hai automatizzato gran parte della scrittura del codice utilizzando gli strumenti CLI di Anthropic, convinto che il sistema gestirà la logica complessa mentre tu ti occupi dell'architettura. Improvvisamente, il terminale si blocca e restituisce un secco Error: Claude Code Process Exited With Code 1. Non c'è una spiegazione dettagliata, solo quel numero uno che indica un fallimento generico. Ho visto sviluppatori perdere intere notti cercando di capire se il problema risiedesse nelle chiavi API, nella configurazione dell'ambiente Node o in un timeout del server. Questo errore specifico non è un semplice bug del software, ma il segnale che il ponte tra il tuo ambiente locale e il modello linguistico si è spezzato per un'incompatibilità che avresti potuto prevedere. Nella maggior parte dei casi, il costo non è solo il tempo perso nel debug, ma la corruzione dei file parzialmente scritti che dovrai ripulire manualmente, raddoppiando il lavoro che cercavi di velocizzare.
La trappola dei permessi e degli ambienti isolati con Error: Claude Code Process Exited With Code 1
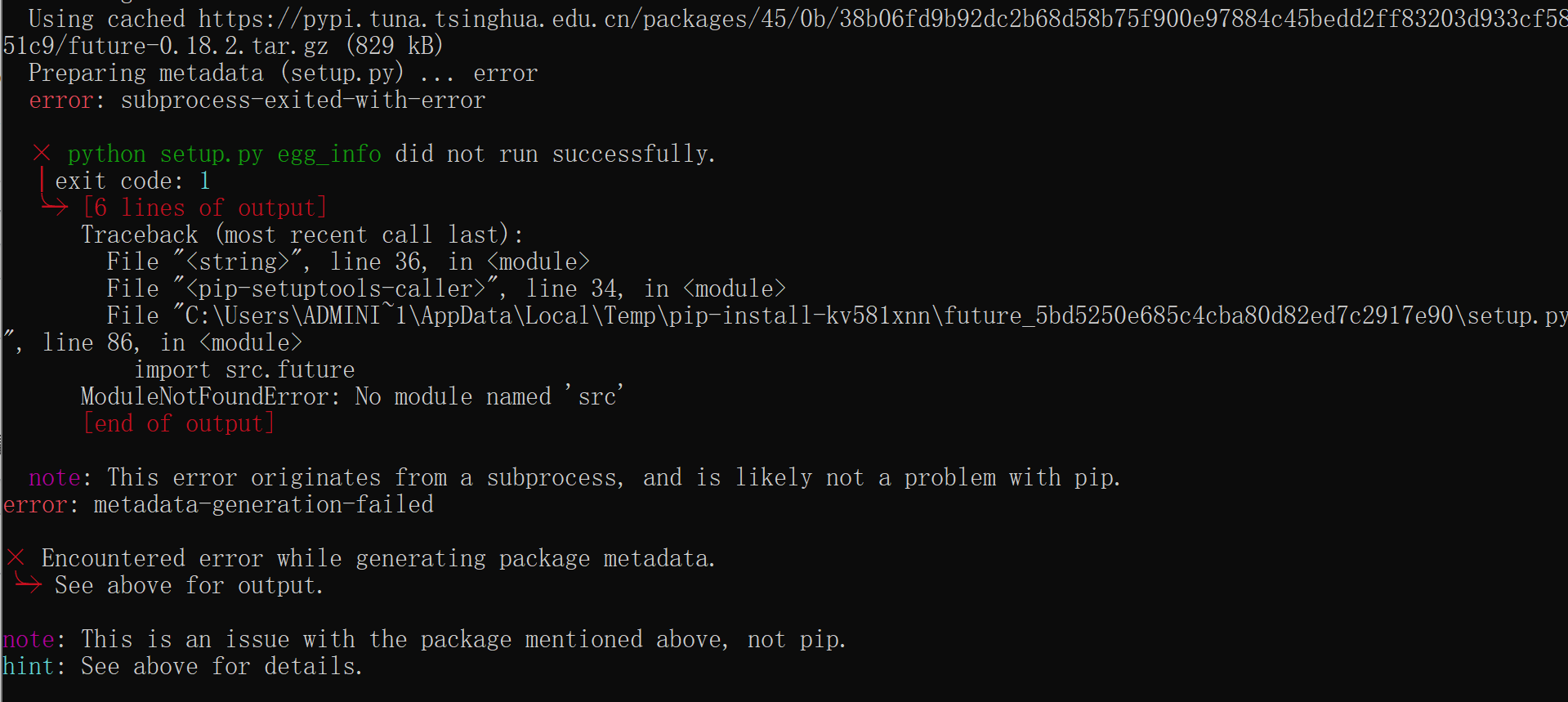
Molti pensano che basti installare il pacchetto e lanciare il comando perché tutto funzioni. Non è così. La causa principale dietro questo arresto anomalo risiede quasi sempre nei permessi di esecuzione o in un ambiente di runtime non correttamente configurato. Quando lanci un'automazione che deve leggere, scrivere ed eseguire file nel tuo file system, il sistema operativo interviene. Se il processo tenta di accedere a una cartella protetta o a un file attualmente bloccato da un altro editor, il programma si chiude bruscamente.
Ho visto aziende investire migliaia di euro in pipeline di integrazione continua che fallivano costantemente perché il container Docker non aveva i privilegi necessari per far girare l'agente. Il codice di uscita 1 è il modo in cui il sistema dice "qualcosa è andato storto all'esterno, non so cosa". Invece di guardare il codice generato, devi guardare i log del sistema operativo. Devi assicurarti che l'utente che esegue il comando abbia i permessi di scrittura nella directory di destinazione e che le variabili d'ambiente siano caricate correttamente nella sessione corrente. Se usi un gestore di versioni per Node, assicurati che la versione attiva sia quella compatibile con le dipendenze dell'agente. Spesso, il problema è banalmente una versione obsoleta di npm che non riesce a risolvere un pacchetto necessario durante l'esecuzione.
Gestione dei file di blocco e processi fantasma
Un altro motivo frequente riguarda i file .lock o i processi rimasti appesi in memoria. Se una sessione precedente si è interrotta male, potrebbero esserci residui che impediscono l'avvio di una nuova istanza. Non cercare soluzioni complicate: pulisci la cache, termina i processi Node orfani e riprova. È una soluzione grezza, ma efficace nel 90% dei casi reali che ho affrontato sul campo.
Ignorare i limiti di quota e i timeout della rete
C'è questa idea sbagliata che i modelli AI siano sempre disponibili e infinitamente veloci. Quando l'agente invia una richiesta massiccia per riscrivere un intero modulo e la tua connessione ha un micro-cedimento, o peggio, superi il limite di token per minuto imposto dal tuo piano, il processo non sempre restituisce un messaggio di errore leggibile. A volte, semplicemente, l'interfaccia a riga di comando non riceve la risposta entro i tempi previsti e crasha. Questo porta inevitabilmente a visualizzare Error: Claude Code Process Exited With Code 1 sul tuo schermo.
Il problema qui è la mancanza di una gestione dei tentativi (retry logic) nel tuo flusso di lavoro. Se lanci comandi pesanti senza monitorare il consumo di token, verrai tagliato fuori a metà dell'opera. Ho visto team di sviluppo impazzire per giorni cercando un bug nel loro codice, quando il problema era semplicemente che stavano inviando troppi dati contemporaneamente, causando il rifiuto della connessione da parte dell'API. Per risolvere, devi frammentare le richieste. Non chiedere all'agente di rifattorizzare cinquantamila righe di codice in un colpo solo. Fallo per moduli, testa ogni passaggio e assicurati che la latenza della rete sia stabile. Se lavori in un ufficio con una connessione ballerina, usa una VPN stabile o assicurati che il tuo firewall non stia ispezionando i pacchetti in modo troppo aggressivo, interrompendo le connessioni lunghe (Keep-Alive).
Errore di sintassi nei prompt e file di configurazione corrotti
Spesso il fallimento non dipende dall'infrastruttura, ma dall'input. Un file di configurazione YAML o JSON scritto male, con una virgola mancante o un'indentazione errata, può far saltare l'intero parser dell'agente. Poiché questi strumenti sono progettati per essere rapidi, a volte il controllo degli errori sull'input è meno descrittivo di quanto vorremmo. Invece di dirti "errore alla riga 12 del file di configurazione", il sistema crasha e basta.
Ho passato ore ad aiutare colleghi che avevano inserito caratteri speciali non supportati nei loro file di istruzioni. L'agente legge il file, incontra un carattere che non sa interpretare e il processo muore. La soluzione è la validazione preventiva. Prima di lanciare qualsiasi automazione su larga scala, passa i tuoi file di configurazione attraverso un linter. Sembra un passaggio in più che rallenta il lavoro, ma ti garantisco che risparmierai ore di frustrazione. Verifica anche che i percorsi dei file definiti nelle tue impostazioni siano assoluti o correttamente relativi alla cartella da cui lanci il comando. Un percorso errato è una garanzia di fallimento immediato.
Confronto tra approccio impulsivo e metodo professionale
Per capire meglio la differenza tra chi fallisce e chi domina questi strumenti, guardiamo come viene gestita una sessione di refactoring su un vecchio database di codice.
L'approccio sbagliato, che ho visto applicare troppe volte, è quello dell'utente che apre il terminale, digita un comando vago per "migliorare tutte le prestazioni del sistema" e preme invio. Non controlla se ci sono file aperti, non verifica lo stato della memoria RAM e non ha un sistema di backup attivo. Il processo inizia a macinare, la ventola del computer accelera e dopo tre minuti appare l'errore fatale. L'utente rimane con metà dei file modificati, alcuni corrotti, e non ha idea di dove il processo si sia fermato. Deve resettare tutto tramite Git, perdendo anche le piccole modifiche manuali fatte in precedenza. È un disastro che costa ore di ripristino.
L'approccio giusto è quello del professionista che prepara il terreno. Prima controlla che la versione del runtime sia corretta. Verifica di avere credenziali API valide e con budget sufficiente. Suddivide il lavoro in piccoli blocchi logici. Lancia il comando su una singola cartella, monitorando l'output in tempo reale. Se il processo si interrompe, sa esattamente quale file stava venendo elaborato. Ha uno script che controlla la sintassi dei file di istruzione prima dell'avvio. In questo modo, anche se si verificasse un problema esterno, il danno è limitato a un singolo modulo facilmente ripristinabile. La differenza non sta nel non incontrare mai l'errore, ma nel rendere l'errore un evento gestibile e non una catastrofe.
Il problema della memoria e del sovraccarico locale
Non dobbiamo dimenticare che questi agenti di codifica non vivono solo nel cloud; una parte significativa della logica di orchestrazione gira sulla tua macchina. Se stai lavorando su un laptop con 8GB di RAM e hai aperto contemporaneamente Chrome con cinquanta schede, Docker, Slack e un IDE pesante come IntelliJ, la tua macchina potrebbe semplicemente terminare il processo per mancanza di risorse. Il sistema operativo invia un segnale di chiusura (SIGKILL o SIGTERM) e il wrapper dell'agente lo interpreta come un'uscita generica.
Dalla mia esperienza, molti crash attribuiti a bug del software sono in realtà problemi di esaurimento delle risorse locali. L'elaborazione del contesto, specialmente se il progetto è vasto, richiede una quantità di memoria non indifferente per indicizzare i file e preparare i prompt da inviare al modello. Se il garbage collector di Node non riesce a stare al passo o se lo spazio su disco nella cartella temporanea è esaurito, l'esecuzione si interromperà. Prima di avviare sessioni lunghe, controlla lo stato della tua macchina. Chiudi ciò che non serve. Sembra un consiglio banale, ma nel mondo della produzione reale, la stabilità dell'ambiente locale è tutto.
Incompatibilità tra versioni del software e dell'agente
Un errore che ho visto costare migliaia di dollari in consulenze riguarda l'aggiornamento automatico degli strumenti. Un lunedì mattina arrivi in ufficio, il tuo strumento CLI si è aggiornato silenziosamente alla versione successiva, ma le tue istruzioni o i tuoi script di automazione sono rimasti alla vecchia sintassi. Lanci il processo e ricevi immediatamente l'errore di uscita.
Le API e gli strumenti CLI basati su modelli linguistici cambiano a una velocità folle. Quello che funzionava tre mesi fa potrebbe essere deprecato oggi. Non dare mai per scontato che il tuo ambiente sia statico. Se lavori in un team, devi bloccare (lock) le versioni degli strumenti di sviluppo. Usa un file package.json o un equivalente per assicurarti che ogni membro del team usi esattamente la stessa versione. Questo evita il classico "sul mio computer funziona" che distrugge la produttività del gruppo. Se vedi che il processo fallisce senza motivo apparente dopo un aggiornamento, fai un downgrade alla versione precedente e verifica se il problema persiste. Spesso scoprirai che è stata introdotta una modifica nella gestione del contesto che rompe i tuoi prompt più complessi.
Una realtà amara sul successo con l'automazione del codice
Smettiamola di pensare che l'AI scriva codice al posto nostro senza supervisione. La verità è che strumenti che possono generare Error: Claude Code Process Exited With Code 1 richiedono più competenza tecnica, non meno. Se non capisci come funziona il tuo file system, come vengono gestite le chiamate API e come leggere un log di sistema, passerai più tempo a combattere con lo strumento che a scrivere codice.
Questi sistemi non sono bacchette magiche. Sono moltiplicatori di forza. Se la tua base di partenza è solida, diventerai dieci volte più veloce. Se la tua base è instabile e le tue conoscenze sistemistiche sono scarse, l'automazione amplificherà solo il tuo disordine. Non esiste una soluzione "clicca e dimentica". Per avere successo devi essere pronto a sporcarti le mani con i file di configurazione, a monitorare i consumi e a gestire manualmente le eccezioni. Chi cerca la via facile verrà punito da errori generici e file corrotti. Chi invece accetta che lo strumento richiede manutenzione e rigore, otterrà risultati che fino a pochi anni fa erano impensabili. Non aspettarti che il software si ripari da solo; impara a capire cosa ti sta dicendo quando smette di funzionare. Solo così smetterai di temere quel codice di uscita e inizierai a usarlo come una bussola per correggere la tua infrastruttura.



