C'è una bugia che l'industria dell'intelligenza artificiale continua a vendere con un'insistenza quasi religiosa: più grande è meglio. Ti dicono che per avere un cervello digitale capace di ragionare, scrivere codice o analizzare documenti legali servono centinaia di miliardi di parametri e server che consumano quanto un piccolo comune della provincia italiana. È una narrazione comoda per chi vende spazio sul cloud, ma ignora una verità brutale che sta emergendo nei laboratori di ricerca più pragmatici. La vera rivoluzione non sta nella potenza bruta, ma nella velocità chirurgica che solo la miniaturizzazione estrema può offrire. Quando cerchi The Faster Llm Ollama Under 3b Params For Fine Tuning non stai solo cercando un software leggero, stai cercando di riprenderti la sovranità tecnologica che le grandi corporation hanno cercato di sequestrare dietro costosi abbonamenti mensili. La velocità di esecuzione su hardware locale, magari quello che hai già sulla scrivania, trasforma l'intelligenza artificiale da un oracolo lontano a uno strumento artigianale che risponde istantaneamente ai tuoi comandi.
Il fallimento della scalabilità indiscriminata
Per anni abbiamo assistito a una corsa agli armamenti che somiglia molto alla crisi dei missili, solo con i chip al posto delle testate nucleari. L'idea dominante era che aumentando la complessità del modello si sarebbe arrivati magicamente all'intelligenza generale. Invece ci siamo ritrovati con mostri digitali che soffrono di allucinazioni persistenti, sono lentissimi da interrogare e impossibili da personalizzare per una piccola impresa o un singolo professionista. Il costo di addestramento di questi giganti è proibitivo, ma il vero salasso arriva dopo, quando devi farli girare. È qui che il castello di carte crolla. Se per ottenere una risposta su un set di dati aziendali devi attendere dieci secondi e pagare ogni singolo token a un fornitore esterno, il valore dell'automazione evapora.
L'efficienza è diventata l'unica metrica che conta davvero nel mondo reale. I modelli che pesano meno di tre miliardi di parametri rappresentano il punto di equilibrio perfetto. Sono abbastanza piccoli da risiedere nella memoria video di una scheda grafica consumer o persino di un laptop moderno, ma abbastanza densi da comprendere sfumature linguistiche complesse una volta che vengono istruiti correttamente. La convinzione che serva un modello enorme per compiti specifici è un errore di valutazione basato sulla pigrizia. Spesso usiamo una motosega per tagliare il pane solo perché non abbiamo voglia di affilare il coltello. Ma nell'informatica l'attrito si paga caro, sia in termini di latenza che di privacy dei dati che finiscono su server oltreoceano.
Perché puntare su The Faster Llm Ollama Under 3b Params For Fine Tuning
Il panorama attuale ci dice che l'ottimizzazione locale vince sulla potenza remota nove volte su dieci. Chi lavora seriamente con i dati sa bene che un modello generico sa tutto di niente, mentre un modello piccolo e specializzato sa tutto di quello che ti serve. Scegliere The Faster Llm Ollama Under 3b Params For Fine Tuning significa puntare su un'architettura che permette cicli di iterazione rapidissimi. Se devi addestrare nuovamente un modello da settanta miliardi di parametri per adattarlo al gergo tecnico della tua azienda, ti serve un budget da multinazionale e settimane di tempo. Se lo fai su una base minuscola, i test durano minuti. Puoi sbagliare, correggere e riprovare dieci volte in un pomeriggio. Questa agilità è l'essenza stessa dell'innovazione, qualcosa che i colossi della Silicon Valley non possono permettersi perché sono prigionieri della propria stessa scala.
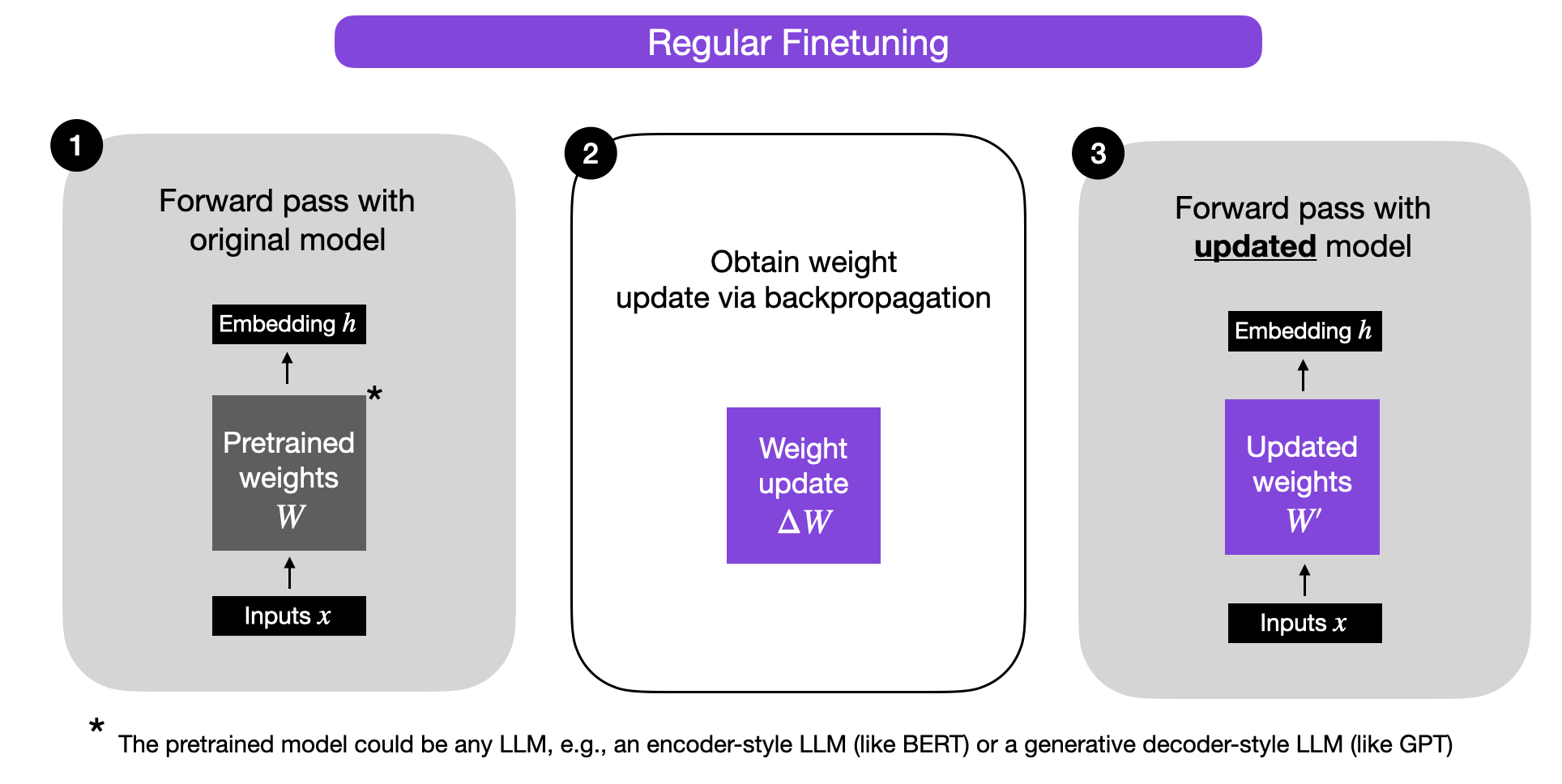
L'adozione di strumenti come Ollama ha rimosso l'ultima barriera che separava lo sviluppatore dal modello: la complessità dell'infrastruttura. Oggi puoi scaricare, avviare e interrogare un'intelligenza artificiale con un singolo comando. Ma il vero salto di qualità avviene quando smetti di usare i modelli pre-addestrati così come sono. Il fine-tuning su piccola scala permette di iniettare conoscenze specifiche, stili di scrittura particolari o protocolli operativi rigidi in un contenitore che risponde a una velocità che i modelli più grandi non possono nemmeno sognare. Non è solo questione di millisecondi risparmiati. È la differenza tra una conversazione fluida con una macchina e un processo a scatti che interrompe il flusso creativo o lavorativo.
La resistenza degli scettici e la realtà dei fatti
Gli esperti che ancora difendono la superiorità dei modelli giganti citano spesso i benchmark standardizzati come prova di eccellenza. Dicono che un modello piccolo non potrà mai superare un test di logica complessa o scrivere una poesia degna di Dante. Hanno ragione, se guardiamo alle capacità generaliste. Ma il punto è proprio questo: a chi serve un'intelligenza artificiale che sa scrivere poesie quando l'obiettivo è classificare migliaia di fatture o estrarre dati da referti medici? Nel momento in cui il perimetro d'azione si restringe, la superiorità dei giganti svanisce. Un modello sotto i tre miliardi di parametri, se addestrato con dati di alta qualità su un compito verticale, spesso batte i fratelli maggiori in termini di precisione e coerenza.
C'è poi il tema della privacy, che in Europa non è un dettaglio ma un obbligo legale e morale. Affidare i segreti industriali o i dati sensibili dei clienti a un'API esterna è un rischio che molte aziende non dovrebbero correre. Gestire tutto internamente, con un consumo energetico ridotto e senza che un solo byte lasci la rete locale, è il vero vantaggio competitivo del prossimo decennio. Gli scettici sostengono che mantenere l'hardware costi troppo, ma dimenticano che il costo di una singola scheda grafica di fascia media si ammortizza in pochi mesi se confrontato con i costi ricorrenti del cloud. È un ritorno alla gestione diretta delle risorse, un passaggio necessario per chiunque voglia mantenere il controllo sulla propria infrastruttura digitale.
L'inganno della complessità necessaria
Molti credono che addestrare un modello piccolo richieda competenze esoteriche che solo pochi eletti possiedono. È una percezione distorta, alimentata da una terminologia inutilmente complicata. La verità è che oggi la soglia d'ingresso si è abbassata drasticamente. La democratizzazione di queste tecnologie passa proprio attraverso la riduzione delle dimensioni. Se il modello è piccolo, la complessità dell'hardware richiesto diminuisce, e con essa la difficoltà di gestione. Non serve più un'intera squadra di ingegneri per mantenere in vita un servizio di intelligenza artificiale. Basta un singolo sviluppatore che sappia come curare il set di dati di addestramento.
L'attenzione si sposta finalmente dalla quantità dei parametri alla qualità dei dati. È un cambio di paradigma che sposta il potere dalle mani di chi possiede i server a quelle di chi possiede la conoscenza. In questo contesto, l'idea di The Faster Llm Ollama Under 3b Params For Fine Tuning diventa un simbolo di efficienza intellettuale. Si smette di inseguire il miraggio di una macchina che pensa come un essere umano per concentrarsi su macchine che risolvono problemi umani in modo rapido e silenzioso. La vera intelligenza non è quella che urla la propria grandezza attraverso statistiche di addestramento astronomiche, ma quella che si inserisce invisibilmente nei nostri processi quotidiani senza appesantirli.
Una scelta di campo tecnologica
Siamo di fronte a un bivio. Da una parte c'è la strada dei modelli monolitici, opachi e centralizzati, dove l'utente è solo un consumatore passivo di un servizio altrui. Dall'altra c'è la via della decentralizzazione, dove ogni computer diventa un nodo di intelligenza autonoma e specializzata. Puntare sui piccoli modelli non è un ripiego per chi non può permettersi il meglio, è una scelta consapevole di chi ha capito che la velocità di esecuzione e la possibilità di personalizzazione valgono molto più di una vaga capacità di rispondere a domande di cultura generale.
Il futuro dell'intelligenza artificiale applicata non si scriverà nei data center immensi nel deserto, ma nei dispositivi che teniamo in tasca o sulle nostre scrivanie. Chi impara oggi a padroneggiare la tecnica del fine-tuning su modelli agili si sta garantendo un vantaggio strategico che durerà anni. Mentre gli altri aspettano che la barra di caricamento del cloud si completi, chi usa modelli ottimizzati ha già finito il lavoro, ha analizzato i risultati e ha spento la macchina. Non c'è gloria nel consumo eccessivo di risorse quando lo stesso risultato si ottiene con una frazione dell'energia e del tempo.
In un mondo che ci spinge a credere che l'unica soluzione sia accumulare potenza, l'atto di scegliere la leggerezza è la mossa più sovversiva e intelligente che si possa compiere. L'intelligenza artificiale non deve essere un gigante che ci sovrasta, ma un bisturi affilato nelle nostre mani. Non abbiamo bisogno di modelli che sappiano tutto, ci servono modelli che sappiano fare bene l'unica cosa che conta davvero per noi in questo preciso momento.
Possedere lo strumento significa non dover mai chiedere il permesso di pensare.



