Le organizzazioni tecnologiche internazionali e le comunità di sviluppatori hanno avviato una revisione dei protocolli di indicizzazione dei dati per ottimizzare le prestazioni dei server aziendali. Durante l'ultima conferenza sulla manutenzione dei sistemi aperti, i rappresentanti della Linux Foundation hanno evidenziato la necessità di integrare strumenti nativi per Find File Linux By Name all'interno delle architetture cloud distribuite. Questa iniziativa risponde a un aumento del 15% nel volume di file non strutturati gestiti dai data center europei nell'ultimo anno, secondo i dati pubblicati da Eurostat. Il coordinamento tra i manutentori del kernel e gli esperti di sicurezza mira a ridurre i tempi di latenza nelle operazioni di recupero delle informazioni critiche per le infrastrutture pubbliche.
L'adozione di metodologie standardizzate per l'individuazione di specifici oggetti digitali rappresenta una priorità per le amministrazioni che migrano verso sistemi operativi liberi. Il rapporto annuale sulla sovranità digitale redatto dall'Agenzia per l'Italia Digitale indica che la corretta configurazione dei comandi di ricerca influisce direttamente sulla produttività dei dipendenti pubblici. Gli ingegneri software incaricati della gestione dei database governativi sottolineano che l'efficienza delle query dipende dalla corretta indicizzazione dei metadati nei file system moderni. Tale processo di modernizzazione richiede una formazione specifica per il personale tecnico addetto alla manutenzione dei nodi di rete nazionali.
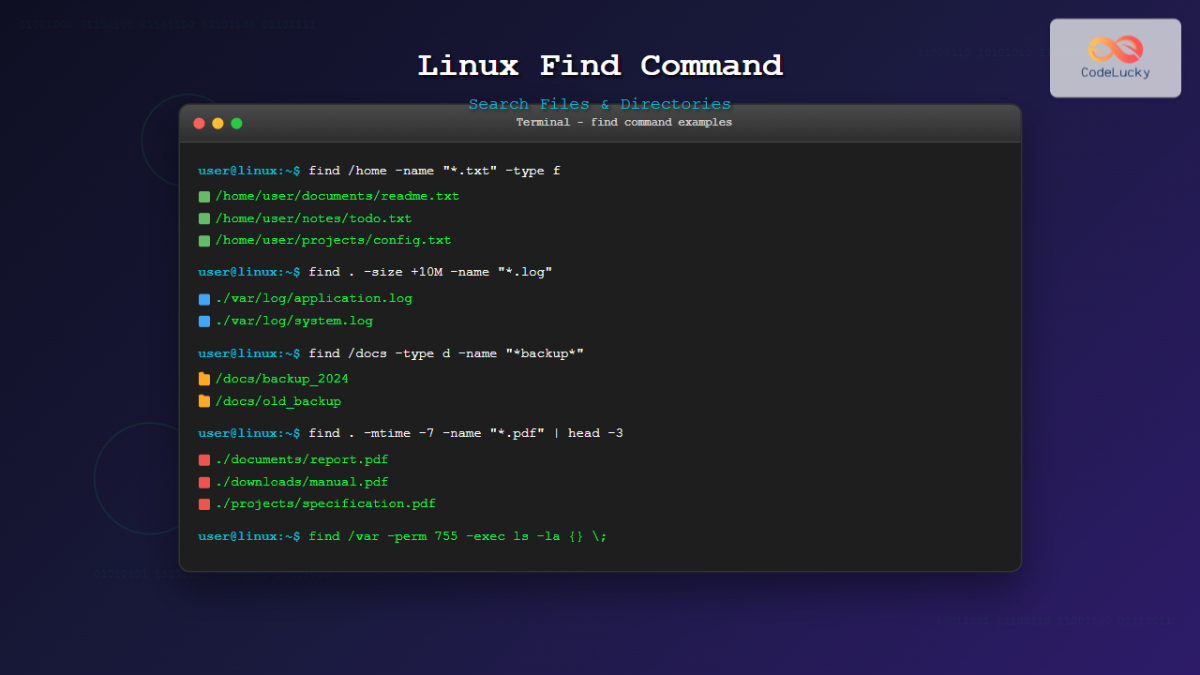
L'Evoluzione Tecnica della Funzione Find File Linux By Name
Il panorama tecnico attuale vede una transizione verso strumenti di ricerca che operano in tempo reale senza sovraccaricare la memoria centrale dei dispositivi. Greg Kroah-Hartman, uno dei principali sviluppatori del kernel, ha spiegato in una recente documentazione tecnica che l'ottimizzazione degli algoritmi di scansione permette di processare milioni di voci in pochi millisecondi. Le nuove versioni delle distribuzioni Debian e Red Hat integrano utility avanzate che semplificano il compito dei sistemisti nel rintracciare configurazioni specifiche in ambienti complessi. La precisione di questi strumenti evita errori di sovrascrittura che potrebbero compromettere l'integrità dei servizi web essenziali.
Le prestazioni delle operazioni di ricerca variano significativamente in base al tipo di file system utilizzato, come Ext4 o Btrfs. Uno studio condotto dal dipartimento di informatica del Politecnico di Milano ha rivelato che la scelta del formato di archiviazione incide fino al 20% sulla velocità di risposta delle chiamate di sistema. Gli accademici hanno osservato che i ritardi nelle operazioni di input e output derivano spesso da una frammentazione eccessiva dei volumi logici non monitorati correttamente. Per mitigare queste inefficienze, le aziende stanno implementando soluzioni di monitoraggio che automatizzano la pulizia dei registri temporanei.
La gestione dei permessi di accesso rimane un elemento centrale nella configurazione degli strumenti di localizzazione dei dati. Secondo il National Institute of Standards and Technology, la configurazione errata delle autorizzazioni di lettura rappresenta una delle vulnerabilità più comuni nei server aziendali. Gli esperti di sicurezza informatica raccomandano di limitare le capacità di scansione profonda solo agli utenti con privilegi elevati per prevenire l'esposizione accidentale di chiavi crittografiche o dati sensibili. La corretta implementazione di questi filtri garantisce che le operazioni di individuazione non diventino un vettore per attacchi interni o esfiltrazione di informazioni.
Analisi delle Prestazioni e Impatto sulle Risorse di Rete
Le aziende di servizi cloud come Amazon Web Services e Microsoft hanno pubblicato linee guida per ottimizzare la ricerca di risorse all'interno delle loro infrastrutture Linux. I dati tecnici forniti da queste piattaforme indicano che una scansione non ottimizzata dell'intera gerarchia delle directory può consumare fino al 40% delle risorse della CPU durante i picchi di carico. Per evitare interruzioni del servizio, i tecnici suggeriscono l'uso di indici precompilati che vengono aggiornati periodicamente durante le ore di minor traffico. Questa strategia permette di bilanciare la rapidità di accesso con la stabilità complessiva del sistema operativo.
L'impiego di Find File Linux By Name in contesti di automazione tramite script richiede una validazione rigorosa per evitare loop infiniti o errori di memoria. Gli ingegneri della Red Hat hanno documentato casi in cui processi di ricerca mal configurati hanno causato il blocco di interi cluster di calcolo ad alte prestazioni. La prevenzione di tali incidenti passa attraverso l'impostazione di limiti temporali e restrizioni sulla profondità delle cartelle analizzate dai comandi di sistema. La standardizzazione di queste pratiche è diventata un requisito per le certificazioni di qualità nei reparti IT delle multinazionali.
Le differenze tra i vari strumenti di ricerca, come quelli basati su database locali o quelli che scansionano direttamente il disco, influenzano la scelta delle architetture hardware. I test di benchmarking effettuati da Phoronix mostrano che i dischi a stato solido con tecnologia NVMe riducono drasticamente i colli di bottiglia durante le ricerche intensive. Le organizzazioni che gestiscono archivi storici digitali stanno investendo nel rinnovo dell'hardware per supportare i nuovi standard di velocità richiesti dalle applicazioni moderne. La rapidità nel trovare un documento specifico in un archivio di petabyte è diventata una metrica fondamentale per valutare l'efficacia dei sistemi di gestione documentale.
Critiche e Limiti delle Soluzioni Tradizionali
Alcuni analisti del settore sottolineano che gli strumenti di ricerca classici faticano a tenere il passo con la crescita esponenziale dei dati generati dai dispositivi Internet delle Cose. Una critica sollevata dai ricercatori della Fondazione Bruno Kessler riguarda la difficoltà di indicizzare contenuti che cambiano con estrema frequenza. Le tecnologie attuali non sempre garantiscono che i risultati di una ricerca riflettano lo stato esatto del file system nell'istante della query. Questa discrepanza temporale può generare errori critici in applicazioni mediche o finanziarie dove la precisione del dato è vitale.
Il consumo energetico derivante dalle continue operazioni di indicizzazione è diventato un tema di discussione nelle politiche di sostenibilità delle grandi aziende tecnologiche. Un rapporto di Greenpeace International ha evidenziato come l'attività incessante dei server dedicata alla gestione dei file contribuisca in modo significativo all'impronta di carbonio del settore digitale. Gli sviluppatori sono quindi chiamati a creare algoritmi più "verdi" che riducano i cicli di calcolo necessari per completare le operazioni di localizzazione. La sfida consiste nel mantenere elevate prestazioni pur operando in un regime di risparmio energetico forzato dalle nuove normative ambientali europee.
La complessità dell'interfaccia a riga di comando rappresenta un'altra barriera per l'adozione diffusa di queste tecnologie tra i professionisti non tecnici. Uno studio sull'usabilità condotto dalla Nielsen Norman Group suggerisce che la curva di apprendimento per i comandi di amministrazione del sistema scoraggia molte piccole imprese dal passaggio a soluzioni open source. Anche se la flessibilità degli strumenti è superiore a quella dei sistemi proprietari, la mancanza di interfacce grafiche intuitive rimane un punto di debolezza. Le comunità di programmatori stanno lavorando a wrapper grafici che rendano accessibili queste potenti funzioni a una platea più vasta di utenti.
Standard di Sicurezza e Protezione dei Metadati
La protezione delle informazioni relative alla struttura dei file è diventata un fronte caldo per la difesa cibernetica delle infrastrutture critiche. Il Regolamento Generale sulla Protezione dei Dati impone requisiti severi sulla visibilità dei nomi dei file che potrebbero contenere dati personali o identificativi. Gli amministratori di sistema devono assicurarsi che i risultati della ricerca non rivelino l'esistenza di documenti riservati a utenti non autorizzati. Questa necessità ha portato allo sviluppo di sistemi di ricerca "consapevoli del contesto" che filtrano i risultati in base all'identità di chi esegue il comando.
L'integrità dei registri di ricerca è fondamentale per le attività di informatica forense condotte dalle autorità di polizia durante le indagini su crimini informatici. Gli esperti della Polizia Postale utilizzano log dettagliati per ricostruire le azioni compiute su un sistema compromesso, inclusi i tentativi di individuare ed eliminare prove digitali. La manipolazione di questi registri da parte di malintenzionati rappresenta un rischio elevato che le nuove versioni del software cercano di prevenire attraverso la firma digitale dei log. La tracciabilità di ogni operazione di sistema è ora considerata uno standard imprescindibile per la sicurezza nazionale.
Le vulnerabilità note nei vecchi motori di ricerca sono state mappate nel database dei Common Vulnerabilities and Exposures. Gli aggiornamenti di sicurezza rilasciati dalle principali distribuzioni puntano a correggere bug che permettevano l'esecuzione di codice arbitrario tramite nomi di file manipolati. La comunità internazionale dei ricercatori in sicurezza monitora costantemente queste falle per fornire patch immediate prima che possano essere sfruttate da attori ostili. La velocità di risposta della comunità open source è spesso citata come un vantaggio competitivo rispetto ai software chiusi dei fornitori commerciali.
Prospettive sulla Gestione Intelligente dei File System
L'integrazione di modelli di intelligenza artificiale per prevedere le necessità di accesso ai file è una delle frontiere più studiate dai centri di ricerca aziendali. Ingegneri presso laboratori come quelli di IBM stanno testando sistemi che pre-caricano i risultati delle ricerche basandosi sulle abitudini passate degli operatori. Questo approccio predittivo potrebbe eliminare del tutto i tempi di attesa, trasformando l'esperienza d'uso dei server in modo radicale. Tuttavia, l'implementazione di tali sistemi richiede una potenza di calcolo che non tutti i centri dati sono attualmente in grado di fornire.
Il passaggio verso il calcolo quantistico pone nuove sfide per la crittografia dei file e, di conseguenza, per la loro rintracciabilità. Gli algoritmi di ricerca attuali dovranno essere completamente riscritti per operare in ambienti post-quantistici dove le protezioni tradizionali potrebbero risultare inefficaci. Organizzazioni come l'Agenzia dell'Unione Europea per la Cibersicurezza stanno già elaborando raccomandazioni per la transizione verso questi nuovi paradigmi tecnologici. La preparazione a questo scenario futuro occupa gran parte dell'agenda dei comitati di standardizzazione tecnica globali.
Nei prossimi mesi, l'attenzione degli osservatori si sposterà sul rilascio delle nuove versioni del kernel Linux, previsto per l'autunno. I gruppi di lavoro continueranno a monitorare l'efficacia delle nuove patch sulle prestazioni dei sistemi di ricerca nei data center ad alta densità. Resta da vedere come le piccole e medie imprese italiane riusciranno ad assorbire queste innovazioni tecniche senza disporre di ampi budget per la formazione. L'evoluzione della sovranità tecnologica europea dipenderà in gran parte dalla capacità di gestire queste risorse digitali in modo sicuro ed efficiente nel lungo periodo.



