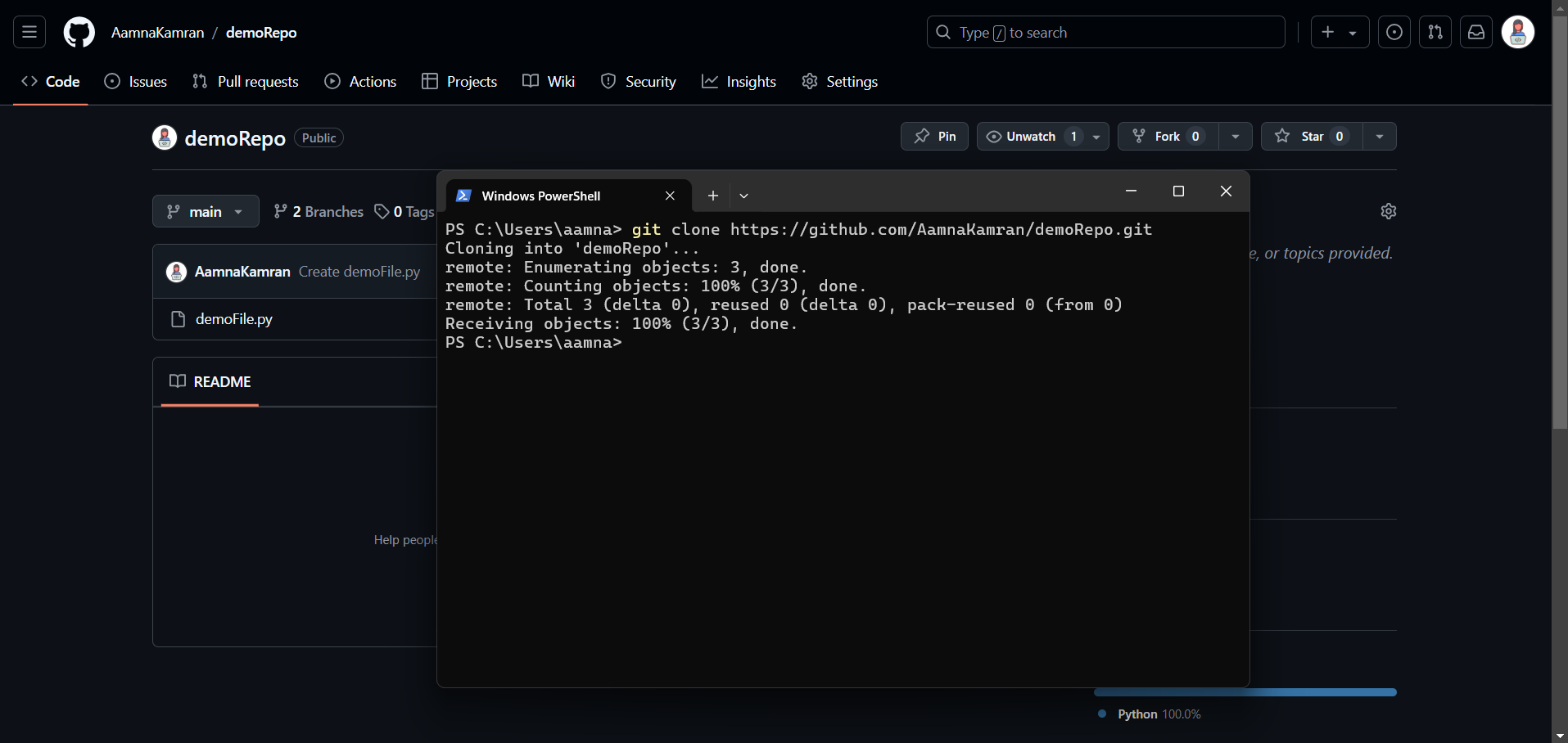
Hai appena terminato una sessione di coding estenuante, il pull request è stato approvato e il merge è andato a buon fine. Con un sospiro di sollievo, digiti il comando per eseguire il Git Delete Branch From Remote e guardi il terminale confermare che quel ramo di sviluppo non esiste più sul server. Ti senti in ordine, metodico, quasi un chirurgo della cronologia del codice. Pensi di aver rimosso ogni traccia di quel lavoro intermedio, lasciando solo la pulizia del ramo principale. Ma ti sbagli di grosso. Quello che la maggior parte degli sviluppatori ignora è che l'eliminazione di un riferimento remoto è poco più di un gesto estetico, un'illusione ottica che non cancella affatto i dati dal server. Credere che rimuovere un puntatore significhi eliminare il codice è come pensare di demolire una stanza semplicemente staccando la targhetta dalla porta. La realtà è che i commit, i file e le modifiche che hai appena "cancellato" fluttuano ancora nel limbo dei server, pronti a essere recuperati da chiunque sappia dove guardare o, peggio, destinati a ingolfare l'infrastruttura per un tempo indefinito.
La cultura del software moderno ci ha insegnato che la pulizia è una virtù, ma ci ha mentito sulla natura della persistenza. Quando interagisci con sistemi distribuiti, la parola cancellazione assume un significato ambiguo, quasi filosofico. Molti credono che mantenere un repository snello sia una questione di igiene digitale, ma spesso è solo una facciata che nasconde una complessità sottostante gestita male. La verità è che il sistema non vuole dimenticare. Ogni volta che cerchi di forzare l'oblio attraverso la rimozione di un ramo, stai solo parlando al database dei riferimenti, non al database degli oggetti. Se pensavi di aver rimosso una vulnerabilità di sicurezza o un segreto caricato per errore eliminando il ramo che lo conteneva, hai appena commesso un errore che potrebbe costarti caro.
L'inganno tecnico dietro il Git Delete Branch From Remote
Per capire perché la tua pulizia è parziale, devi smettere di guardare Git come un semplice archivio di cartelle e iniziare a vederlo per quello che è: un database di oggetti mappati tramite hash. Quando esegui il Git Delete Branch From Remote, stai inviando un pacchetto di rete al server che dice essenzialmente di rimuovere un file di testo molto piccolo situato nella cartella dei riferimenti remoti. Quel file contiene solo l'identificativo dell'ultimo commit del ramo. Una volta rimosso il file, il ramo sparisce dall'interfaccia di GitHub, GitLab o Bitbucket, ma i commit che componevano quel ramo restano lì, intatti. Sono diventati quelli che in gergo chiamiamo commit orfani o "dangling commits". Non sono visibili attraverso i comandi standard di esplorazione, ma occupano spazio e, cosa più importante, sono ancora accessibili se conosci il loro codice identificativo.
Il server non ha alcun interesse a eliminare immediatamente quegli oggetti. Farlo richiederebbe un'operazione costosa chiamata garbage collection, che i provider di hosting eseguono raramente e con criteri molto conservativi. Io ho visto intere aziende convinte di aver protetto la propria proprietà intellettuale cancellando rami sperimentali, solo per scoprire che quegli stessi dati erano ancora scaricabili tramite semplici chiamate API o clonando il repository con flag specifici. La persistenza è il default, l'eliminazione è l'eccezione. Questa discrepanza tra ciò che il comando suggerisce e ciò che il server esegue realmente crea una zona d'ombra pericolosa dove la falsa sicurezza regna sovrana.
Il meccanismo di puntamento è la forza di questo strumento, ma è anche il suo più grande inganno per l'utente inesperto. Se un altro sviluppatore ha scaricato quel ramo sul proprio computer locale prima della tua operazione di pulizia, quel ramo continuerà a vivere nel suo spazio di lavoro. La prossima volta che quella persona farà un push, c'è una probabilità non nulla che quei riferimenti tornino a infestare il server, rendendo il tuo sforzo del tutto vano. È una battaglia contro l'idra: tagli una testa e ne spuntano altre due nelle workstation dei tuoi colleghi. La gestione remota non è un'azione unilaterale, è un consenso distribuito che spesso manca di un'autorità centrale capace di imporre l'oblio totale.
La gestione dei rifiuti digitali e il mito dello spazio risparmiato
Esiste una credenza diffusa secondo cui eliminare rami remoti serva a mantenere le prestazioni del repository elevate. Si sente spesso dire che troppi rami rallentano le operazioni di fetch o rendono il grafo dei commit illeggibile. Sebbene la leggibilità umana sia un punto valido, l'argomento delle prestazioni è quasi sempre una sciocchezza tecnica. I moderni sistemi di controllo versione gestiscono migliaia di riferimenti con un impatto minimo sulla latenza. Il vero costo non è nel numero di rami, ma nella dimensione degli oggetti memorizzati. Poiché l'azione di rimozione non elimina gli oggetti, non stai risparmiando nemmeno un byte di spazio sul server nel momento in cui premi invio.
Io mi sono trovato spesso a discutere con team leader ossessionati dalla pulizia dei rami che ignoravano completamente la presenza di file binari enormi nella cronologia principale. È un paradosso cognitivo. Ci si concentra sulla rimozione di un puntatore testuale da pochi byte e si ignorano gigabyte di dati inutili sepolti nei commit passati. Se il tuo obiettivo è la performance, dovresti guardare altrove. Dovresti studiare come riscrivere la cronologia, come usare strumenti per filtrare il contenuto dei pacchetti o come gestire i file di grandi dimensioni esternamente. La rimozione di un ramo remoto è un placebo per l'ansia da disordine, non una strategia di ottimizzazione dell'infrastruttura.
C'è poi la questione del tracciamento storico. In molti settori regolamentati, la tendenza aggressiva a eliminare ogni traccia del lavoro intermedio può diventare un problema legale o di conformità. Se un bug critico emerge tra sei mesi, avere accesso ai rami di sviluppo originali, con i loro commenti e i loro tentativi falliti, può essere la chiave per capire la genesi dell'errore. Cancellando tutto ciò che non è il ramo principale, stai distruggendo il contesto. Stai bruciando le bozze di un libro tenendo solo la versione stampata, rendendo impossibile capire perché certe decisioni siano state prese. Questa ossessione per la "cronologia pulita" è spesso una forma di vanità tecnica che sacrifica la sicurezza e la tracciabilità sull'altare dell'estetica.
Perché la tua strategia di sicurezza basata sui rami è destinata al fallimento
Il punto più critico riguarda la sicurezza dei dati sensibili. Immagina uno scenario comune: uno sviluppatore carica per sbaglio una chiave API privata o una password di database in un ramo di feature. Accortosi dell'errore, pensa che la soluzione sia eseguire un Git Delete Branch From Remote per far sparire il segreto prima che qualcuno lo veda. Questa è la ricetta per il disastro. Poiché quegli oggetti rimangono nel database del server, qualsiasi utente malintenzionato che abbia accesso al repository può ancora recuperare quel segreto. Esistono bot che scansionano i repository in tempo reale proprio alla ricerca di commit orfani o di reflog accessibili.
La sicurezza informatica non si fa con la gomma da cancellare, si fa con la sovrascrittura o con la rotazione delle credenziali. Una volta che un dato è stato spinto sul server, devi considerarlo compromesso. Non importa quanto velocemente tu agisca per eliminare il riferimento. La struttura stessa del sistema è progettata per essere immutabile e resistente alla perdita di dati, il che significa che è anche intrinsecamente resistente ai tuoi tentativi di rimediare agli errori di sicurezza tramite la semplice eliminazione. Le aziende spendono milioni in audit di sicurezza, ma spesso i buchi più grandi sono causati da questa incomprensione fondamentale su come il codice viene effettivamente rimosso o conservato.
Per risolvere davvero un problema di questo tipo, bisognerebbe utilizzare strumenti di "force-push" pesanti dopo aver riscritto l'intera cronologia con utility specifiche, un processo che invalida il lavoro di tutti gli altri membri del team e che comunque non garantisce l'eliminazione dei dati dai backup del provider. La lezione è amara ma necessaria: la trasparenza di Git è un'arma a doppio taglio. Quello che viene percepito come un ambiente privato e controllabile è in realtà un ecosistema dove ogni azione lascia una scia indelebile, e il comando di rimozione è solo un velo sottile steso sopra un archivio permanente.
Il ruolo della collaborazione e il conflitto dei riferimenti locali
Un altro aspetto che viene regolarmente sottovalutato è l'attrito che la rimozione remota crea nel flusso di lavoro di un team distribuito. Quando tu elimini un ramo sul server, non stai notificando automaticamente i computer dei tuoi colleghi. Loro continueranno a vedere quel ramo nei loro elenchi locali finché non eseguiranno manualmente un'operazione di "prune". Questo scollamento tra lo stato reale del server e lo stato percepito dai singoli sviluppatori è una fonte costante di confusione e di errori di merge. Mi è capitato di vedere interi pomeriggi persi perché qualcuno stava cercando di inviare modifiche a un ramo che non esisteva più, o peggio, qualcuno che ricreava inavvertitamente un ramo eliminato con versioni obsolete del codice, sovrascrivendo ore di lavoro di altri.
Questo accade perché il sistema non ha un concetto di "morte" definitiva per un ramo. Un ramo è solo un nome. Se io creo un ramo con lo stesso nome di quello che hai appena rimosso, per il sistema quel ramo è una continuazione o una reincarnazione, non un'entità nuova. Questa ambiguità semantica è ciò che rende la gestione dei rami remoti così fragile. Invece di concentrarsi sul comando atomico di cancellazione, i team dovrebbero investire in politiche di denominazione e cicli di vita del software che accettino la natura effimera dei rami senza pretendere di controllarne la persistenza fisica.
Il conflitto non è solo tecnico, è comunicativo. L'atto di eliminare un ramo è un messaggio silenzioso. Se non è accompagnato da una comunicazione chiara, lascia gli altri membri del team nel dubbio. Era un ramo finito? Era un esperimento fallito? È stato rimosso per errore? In un mondo dove la collaborazione asincrona è la norma, affidarsi a un comando del terminale per comunicare lo stato di un progetto è una scelta pigra che porta inevitabilmente a malintesi. La pulizia del repository dovrebbe essere il risultato di un processo decisionale condiviso, non l'iniziativa solitaria di chi vuole vedere meno righe nel proprio terminale.
Verso una nuova consapevolezza della struttura del codice
Dobbiamo smettere di trattare il nostro sistema di controllo versione come un giocattolo e iniziare a trattarlo come un registro contabile. In contabilità, non si cancella mai nulla; si fanno scritture di storno. Git funziona in modo molto simile. Ogni azione che compi è un'aggiunta di informazioni, anche quando l'azione stessa riguarda una rimozione. La consapevolezza che tutto resta, che ogni commit è una cicatrice permanente e che i rami sono solo etichette adesive scambiate tra computer, cambia radicalmente il modo in cui scrivi il codice.
Invece di preoccuparti di come eliminare le tracce, dovresti preoccuparti di non lasciarne di imbarazzanti. La disciplina nel commit, l'uso di messaggi descrittivi e la separazione netta tra segreti e logica di business sono le uniche vere difese. La prossima volta che ti trovi a digitare quel comando per pulire il server, fallo pure, ma con la consapevolezza che stai solo riordinando la scrivania, non svuotando il cestino della carta straccia. La tua eredità digitale è molto più profonda e persistente di quanto quel messaggio di conferma nel terminale voglia farti credere.
Il futuro dello sviluppo non risiede nella capacità di nascondere i nostri errori sotto il tappeto di un comando di rimozione, ma nella capacità di gestire un flusso di dati infinito e permanente con onestà tecnica. La pulizia del codice non è l'assenza di rami vecchi, è la presenza di una struttura logica che resiste al tempo e alla confusione, indipendentemente da quanti puntatori orfani fluttuano nell'ombra dei tuoi server. Accettare questa realtà significa diventare sviluppatori migliori, più attenti e meno illusi da una semplicità superficiale che nasconde una complessità spietata.
Il codice non muore mai davvero, rimane in attesa di essere riscoperto tra le pieghe di un database che non sa cosa significhi dimenticare.



