Hai appena iniziato a lavorare su quel progetto che sognavi da mesi. Il team è carico, il repository su GitHub è pieno di commit e tu devi assolutamente scaricare le ultime modifiche fatte dal tuo collega senior per non restare indietro. Apri il terminale, senti il peso della responsabilità e capisci che è il momento di eseguire Git Pull A Remote Branch per allineare il tuo ambiente di sviluppo locale con quello che succede sul server. Non è solo questione di scaricare file. Si tratta di mantenere l'integrità del tuo lavoro. Se sbagli questo passaggio, rischi di finire in un labirinto di conflitti di merge che ti porteranno via ore di sonno e litri di caffè. La gestione dei rami remoti è il cuore pulsante della collaborazione moderna nello sviluppo software.
Perché la sincronizzazione dei rami è il pilastro del lavoro in team
Lavorare da soli è facile. Quando sei l'unico a toccare il codice, Git sembra quasi un optional di lusso. Ma quando entri in una realtà aziendale o in un progetto open source serio, la musica cambia. La capacità di recuperare aggiornamenti specifici da un server remoto senza sporcare il proprio flusso di lavoro è ciò che separa i dilettanti dai professionisti. Spesso si pensa che basti un comando generico per sistemare tutto. Sbagliato. Bisogna capire cosa succede sotto il cofano.
Quando interagisci con un server, che sia su GitHub o su un'istanza privata di GitLab, non stai solo copiando dati. Stai istruendo il tuo sistema locale a confrontare due storie diverse. Quella che hai scritto tu sul tuo portatile e quella che il resto del mondo ha approvato sul server centrale. Questa discrepanza può essere minima o enorme. Ignorarla significa andare incontro a bug che appariranno solo in produzione, ovvero il peggior incubo di ogni sviluppatore.
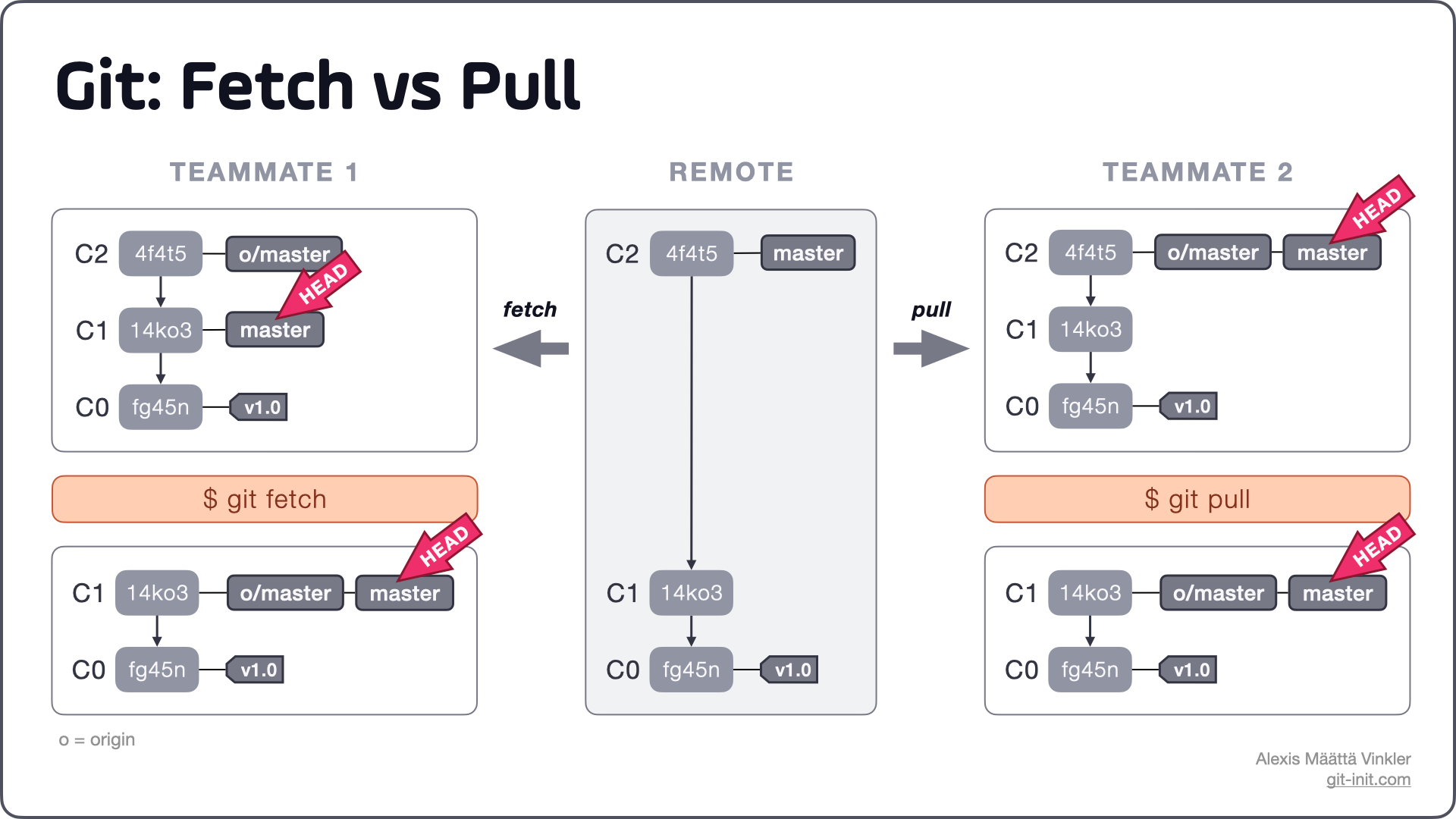
La differenza tra fetch e pull che molti ignorano
C'è un equivoco che gira spesso negli uffici: usare i due comandi come se fossero sinonimi. Non lo sono affatto. Il fetch è come guardare la vetrina di un negozio senza entrarci. Scarichi le informazioni su cosa è cambiato, vedi i nuovi rami, ma il tuo codice locale non viene toccato. È un'operazione sicura. Il pull, invece, è l'azione di chi entra nel negozio, compra e porta tutto a casa immediatamente.
Il pull combina due operazioni: il recupero dei dati e l'unione automatica. Questo automatismo è comodo ma pericoloso. Se non sai esattamente cosa stai portando dentro, potresti sovrascrivere funzioni che stavi testando. Molti esperti preferiscono fare prima un controllo dei metadati per evitare sorprese. È una questione di controllo. Se vuoi dormire tranquillo, devi sapere cosa sta per atterrare sul tuo disco rigido.
Gestire i conflitti prima che diventino ingestibili
I conflitti capitano. È un dato di fatto. Succedono quando due persone modificano la stessa riga dello stesso file. Git è intelligente, ma non sa leggere nel pensiero. Non può sapere se la tua logica è migliore di quella del tuo collega. Quando accade, il processo si ferma. Ti trovi davanti a quei segni strani nel codice che indicano le due versioni contrastanti.
Il segreto per gestire queste situazioni è la frequenza. Più spesso aggiorni il tuo ramo locale, meno cambiamenti accumuli. Meno cambiamenti significano meno probabilità di sovrapposizioni dolorose. Chi aspetta una settimana prima di sincronizzarsi sta praticamente chiedendo guai. Un aggiornamento quotidiano, invece, rende i conflitti piccoli, granulari e facili da risolvere in pochi minuti.
Come configurare correttamente Git Pull A Remote Branch nel tuo flusso quotidiano
Per eseguire correttamente l'operazione di recupero, devi prima assicurarti che il tuo ambiente conosca l'esistenza del ramo remoto. Spesso capita di provare a scaricare qualcosa che il nostro computer non vede ancora. Il comando deve essere preciso. Non puoi sperare che il sistema indovini quale parte del server ti serve. Devi essere esplicito.
Configurazione delle origini remote
Prima di tutto, controlla i tuoi "remote". Di solito il server principale si chiama origin. Puoi vederlo con un comando rapido che elenca gli URL associati. Se lavori su un fork, potresti avere anche un "upstream". Sapere da dove arrivano i dati è il primo passo. Se cerchi di scaricare da un'origine che non esiste, riceverai un errore che potrebbe confonderti se sei alle prime armi.
Un errore comune è dimenticare di aggiornare l'elenco dei rami disponibili. Se un collega ha creato una nuova funzionalità dieci minuti fa, il tuo Git locale non lo sa ancora. Devi prima fare una scansione del server. Solo dopo questa operazione il nuovo percorso diventerà visibile e potrai finalmente portarlo sul tuo PC per iniziare a lavorarci o per testarlo.
Il ruolo del tracking branch
Un concetto che molti saltano è quello del tracking. Quando crei un legame tra il tuo ramo locale e quello remoto, rendi tutto più semplice. Git memorizza questa relazione. Da quel momento, potrai usare comandi abbreviati perché il sistema sa già a chi "chiedere" gli aggiornamenti. È come impostare un contatto preferito sul telefono invece di digitare ogni volta il numero completo.
Senza questo legame, ogni operazione diventa più lunga e soggetta a refusi. Impostare correttamente il tracking all'inizio ti risparmia migliaia di battute sulla tastiera nel corso di un anno di lavoro. È un investimento di tre secondi che paga dividendi altissimi in termini di produttività e salute mentale.
Strategie avanzate per evitare il caos nel repository
Non tutti i modi di scaricare aggiornamenti sono uguali. Esistono filosofie diverse su come la cronologia del progetto dovrebbe apparire. C'è chi preferisce vedere ogni singolo merge, creando quel grafico a ragnatela tipico dei grandi progetti, e chi invece vuole una linea pulita, dritta e leggibile.
Rebase contro Merge la sfida eterna
Questa è la discussione che anima le pause pranzo dei programmatori. Il merge crea un nuovo commit che unisce le due strade. È fedele alla realtà storica: dice chiaramente che in quel momento hai unito i pezzi. Però, rende la cronologia disordinata se ci sono troppi rami piccoli. Il rebase, al contrario, riscrive la storia. Prende i tuoi commit e li sposta "sopra" gli ultimi arrivati dal server.
Il risultato del rebase è una linea temporale pulitissima. Sembra che tu abbia scritto il codice partendo dall'ultima versione disponibile, anche se in realtà avevi iniziato tre giorni prima. Ma attenzione: il rebase non va mai usato su rami pubblici o condivisi. Riscrivere la storia di qualcosa che altri stanno usando è il modo più veloce per farsi odiare da tutto il team. Usalo solo sul tuo ramo privato prima di inviare i risultati finali.
Usare lo Stash per pulire il tavolo da lavoro
Ti è mai capitato di dover scaricare un aggiornamento urgente ma di avere il lavoro a metà? Non vuoi fare un commit perché il codice non funziona ancora, ma Git non ti permette di fare il pull perché i file sono sporchi. Qui entra in gioco lo stash. È come un cassetto dove butti temporaneamente i tuoi attrezzi per liberare il tavolo.
Metti tutto nello stash, il tuo spazio di lavoro torna pulito, scarichi le novità del team e poi riprendi le tue modifiche dal cassetto. È una manovra fluida che ti permette di reagire alle emergenze senza sporcare la cronologia del progetto con commit inutili del tipo "salvataggio temporaneo" o "work in progress".
Errori tipici che bloccano la produttività
Anche i programmatori più esperti cadono in trappole banali. La fretta è la nemica numero uno. Spesso si preme invio senza leggere i messaggi di errore, pensando che sia il solito avviso di routine. Invece, Git ci parla costantemente. Ignorare i suoi messaggi è come ignorare la spia dell'olio nella macchina.
Dimenticare i sottomoduli
Se il tuo progetto usa altri progetti al suo interno, la situazione si complica. Un semplice aggiornamento del ramo principale potrebbe non bastare. Se i riferimenti ai sottomoduli cambiano sul server ma tu non li aggiorni localmente, il progetto smetterà di compilare. Ti ritroverai con versioni incoerenti e passerai ore a cercare un bug nel tuo codice quando in realtà è solo una dipendenza non aggiornata.
Esistono opzioni specifiche per dire a Git di aggiornare tutto in modo ricorsivo. È fondamentale conoscerle se lavori in ecosistemi complessi come quelli dello sviluppo di videogiochi o di grandi applicazioni enterprise. La coerenza del sistema dipende dalla tua capacità di orchestrare tutti questi pezzi in movimento.
Conflitti di permessi e chiavi SSH
A volte il problema non è il codice, ma l'accesso. Se cambi computer o se i permessi del repository vengono modificati, l'operazione Git Pull A Remote Branch fallirà miseramente. Spesso il colpevole è una chiave SSH scaduta o non configurata correttamente nel tuo profilo. Molti sviluppatori perdono tempo a controllare i rami quando il problema è semplicemente che il server non li riconosce più.
Controllare regolarmente le proprie credenziali e usare gestori di password sicuri o agenti SSH è parte integrante del lavoro. In Italia, molte aziende stanno adottando standard di sicurezza più rigidi, seguendo le direttive europee sulla protezione dei dati e sulla sicurezza informatica, come previsto dal Cyber Resilience Act. Assicurati che i tuoi protocolli di connessione siano aggiornati per evitare interruzioni improvvise.
Ottimizzare le prestazioni su repository giganti
Se lavori su un progetto con migliaia di file e anni di storia, ogni operazione può diventare lenta. Scaricare gigabyte di dati ogni volta non è efficiente. Fortunatamente, ci sono modi per rendere tutto più snello. Non serve avere l'intera storia dell'umanità sul proprio laptop se ti serve solo modificare un'icona.
Shallow clone e pull parziali
Puoi decidere di scaricare solo gli ultimi commit. Si chiama "shallow clone". Riduce drasticamente il tempo di attesa e lo spazio occupato sul disco. È utilissimo per le macchine di integrazione continua (CI/CD) che devono solo testare l'ultima versione e non hanno bisogno di sapere cosa è successo nel 2015.
Allo stesso modo, puoi configurare Git per ignorare certe cartelle pesanti che non ti servono. Se sei un programmatore backend, forse non ti serve scaricare tutti gli asset grafici in alta risoluzione che pesano quanto un intero sistema operativo. Meno dati sposti, più velocemente lavori. La velocità del terminale influisce direttamente sul tuo stato di "flow".
L'importanza di una connessione stabile
Potrebbe sembrare scontato, ma la qualità della tua rete conta. Se lavori da remoto, magari da una zona con scarsa copertura, le operazioni pesanti possono interrompersi a metà, lasciando il repository in uno stato inconsistente. Usare connessioni protette e stabili è la base. In Italia, il piano per la banda ultra-larga sta migliorando la situazione, ma è sempre bene avere un piano B se la connessione principale salta durante un aggiornamento critico.
Come comportarsi in caso di emergenza
Cosa fai se dopo un aggiornamento tutto smette di funzionare? Niente panico. Git ha una funzione fantastica chiamata reflog. È una sorta di scatola nera che registra ogni singolo spostamento del puntatore del tuo repository. Anche se hai fatto un merge disastroso o hai cancellato un ramo per sbaglio, il reflog può salvarti la vita.
Ti permette di tornare indietro nel tempo a un istante prima del disastro. È lo strumento definitivo per chi sperimenta. Sapere di avere questa rete di sicurezza ti permette di essere più audace e di imparare più velocemente. Non aver paura di rompere le cose, purché tu sappia come ripararle. La padronanza di questi strumenti di recupero è ciò che definisce un esperto.
Verificare l'integrità dei dati
Dopo un'operazione complessa, è buona norma lanciare un comando di controllo per assicurarsi che non ci siano oggetti corrotti. Succede raramente, ma quando succede sono dolori. Un controllo rapido ti dà la certezza matematica che il tuo database locale sia in salute. La prevenzione è sempre meglio della cura, specialmente quando si parla di codice sorgente che vale migliaia di euro.
Passi pratici per una sincronizzazione perfetta
Non limitarti a leggere. La teoria senza pratica è inutile nello sviluppo software. Ecco una sequenza logica che dovresti seguire ogni volta che ti approcci al tuo terminale per allinearti con il resto del mondo.
- Assicurati di non avere modifiche pendenti non salvate. Usa lo stash se necessario per pulire la tua area di lavoro corrente senza perdere i progressi.
- Controlla su quale ramo ti trovi. Sembra banale, ma scaricare codice nel posto sbagliato è l'errore più frequente in assoluto.
- Esegui un fetch preventivo. Guarda cosa sta succedendo sul server GitSCM ufficiale per capire l'entità dei cambiamenti in arrivo.
- Valuta se preferisci un merge o un rebase. Se il tuo ramo è solo tuo e non lo hai ancora condiviso, il rebase è spesso la scelta più pulita.
- Avvia l'aggiornamento vero e proprio verso il tuo obiettivo locale.
- Risolvi immediatamente eventuali conflitti. Non rimandarli. Più aspetti, più perdi il contesto di quello che stavi scrivendo.
- Esegui i test automatici. Anche se il merge è andato a buon fine senza conflitti testuali, potrebbero esserci conflitti logici (una funzione rinominata da un lato e chiamata col vecchio nome dall'altro).
- Una volta che tutto è verde e funzionante, puoi riprendere il tuo lavoro da dove lo avevi lasciato, con la certezza di essere sulla cresta dell'onda tecnologica del tuo team.
Seguire questo schema trasformerà un'operazione potenzialmente stressante in una routine noiosa ma sicura. E nel mondo della programmazione, "noioso" significa che le cose funzionano esattamente come dovrebbero. Non c'è complimento migliore per un flusso di lavoro.



