Hai appena iniziato il turno, il caffè è ancora bollente sulla scrivania e apri il terminale convinto che il tuo codice sia perfetto. Poi provi a spingere le modifiche e il sistema ti rimbalza con un errore rosso sangue perché un collega ha stravolto tutto mentre dormivi. Succede ogni giorno. Sapere come gestire un Git Pull From A Remote Branch non è solo un esercizio di stile per programmatori pignoli, ma la differenza tra una giornata produttiva e tre ore passate a risolvere conflitti di merge che non dovrebbero esistere. La gestione dei rami remoti è il cuore del lavoro collaborativo. Se non la domini, finisci per rompere il flusso di lavoro di tutti.
Molti sviluppatori alle prime armi pensano che basti scrivere un comando generico e sperare che il software faccia la magia. Non funziona così. Quando interagisci con un server esterno, come quelli di GitHub, stai chiedendo al tuo computer di sincronizzare due stati mentali diversi: il tuo e quello del resto della squadra. Questo processo richiede precisione. Devi sapere esattamente da dove stai prendendo i dati e dove li stai mettendo. Se sbagli mira, rischi di sovrascrivere funzioni vitali o di ritrovarti con un "detatched HEAD" che ti farà sudare freddo.
Come funziona davvero il recupero dei dati
Sotto il cofano, questo meccanismo non è un singolo movimento. Si tratta di una combinazione di due azioni distinte: il recupero dei metadati e l'unione dei file. Quando esegui l'operazione, il software scarica le modifiche dal server e cerca immediatamente di integrarle nel tuo ramo attuale. È qui che nascono i problemi. Se hai modifiche locali non salvate, il sistema si blocca. Se il server ha una storia divergente, si apre l'editor di testo per chiederti spiegazioni. Capire questa dualità ti permette di anticipare gli errori invece di subirli.
Spesso mi chiedono perché non usare semplicemente il tasto "Sync" negli ambienti di sviluppo grafici. La risposta è semplice: il terminale non mente. Usando la riga di comando hai il controllo totale sui parametri. Puoi decidere di ripulire i rami che non esistono più sul server o di forzare un aggiornamento che ignori le tue modifiche locali se sai che sono spazzatura. La consapevolezza tecnica batte la comodità visiva ogni volta che la scadenza di un progetto si avvicina.
Strategie avanzate per gestire un Git Pull From A Remote Branch senza fare danni
Esistono diversi modi per portare a termine questa missione. Il metodo standard è quello che tutti imparano il primo giorno, ma raramente è il più pulito per la cronologia del progetto. Immagina di lavorare su una funzionalità complessa. Se continui a importare modifiche dal ramo principale usando il metodo classico, la tua storia dei commit diventerà un groviglio illeggibile di messaggi "Merge branch...". Questo rende impossibile fare il debugging a ritroso se qualcosa si rompe tra un mese.
Una tecnica molto più elegante prevede l'uso del rebase. Invece di creare un nuovo punto di unione, sposti le tue modifiche in cima a quelle scaricate dal server. Il risultato è una linea retta, pulita e facile da leggere. C'è un rischio, però. Non devi mai farlo su rami condivisi dove altri stanno lavorando, altrimenti riscrivi la storia per tutti e i tuoi colleghi ti odieranno. La regola d’oro è: usa il rebase per i tuoi rami locali e il merge per integrare il lavoro finito nel ramo principale del team.
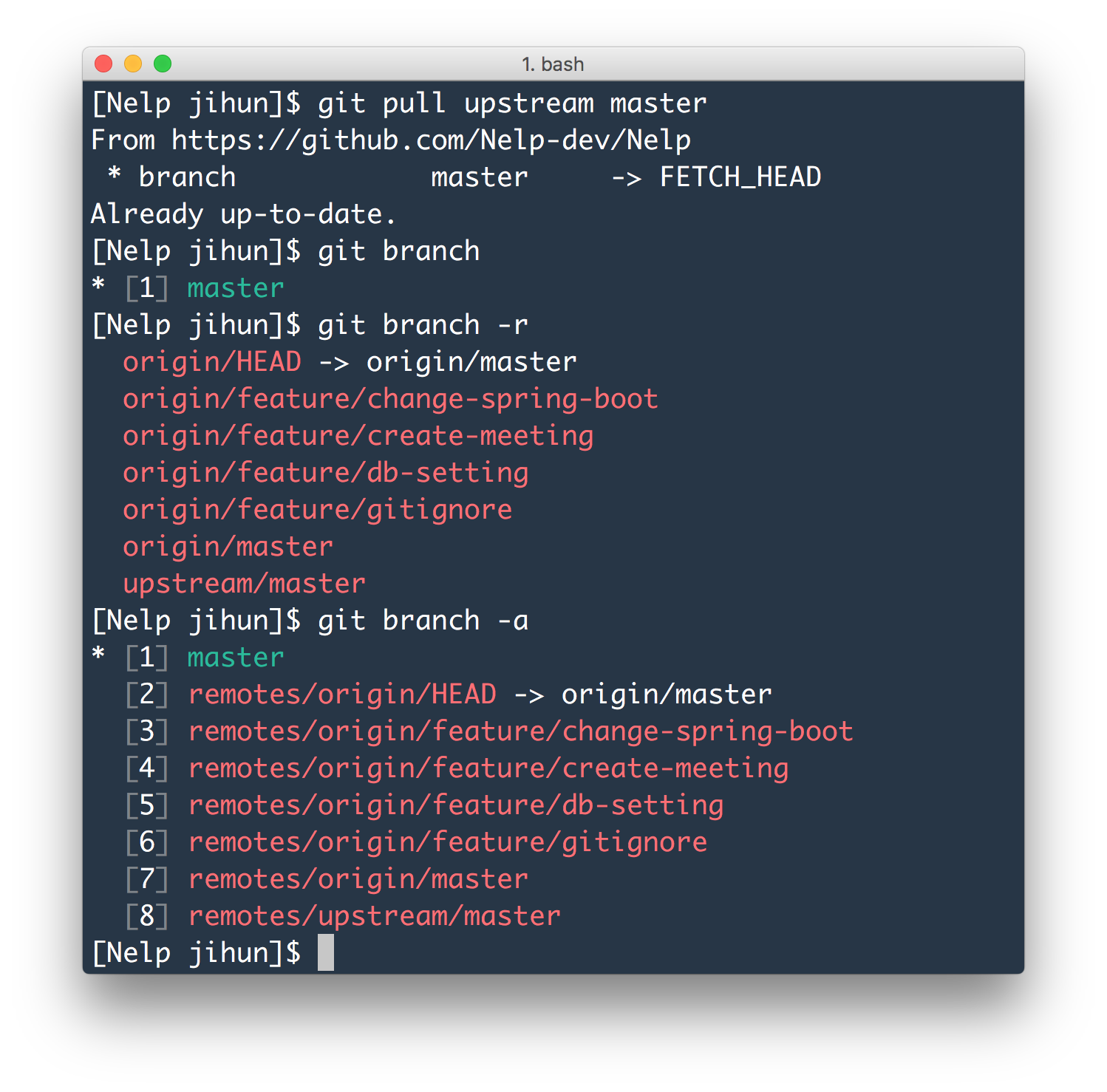
Gestire le discrepanze tra nomi locali e remoti
Un errore classico capita quando il nome del tuo ramo sul computer non corrisponde a quello sul server. Magari hai chiamato la tua cartella di lavoro "fix-bug" ma sul server qualcuno l'ha rinominata "issue-402". Se provi a sincronizzare senza specificare le origini, il comando fallirà miseramente. Devi essere esplicito. Devi dire al sistema: prendi i dati da questa origine specifica e portali qui.
Questa precisione serve anche quando vuoi testare il lavoro di un altro sviluppatore. Non hai bisogno di avere quel ramo già presente sul tuo PC. Puoi tirarlo giù direttamente indicando il nome remoto. È una manovra rapida che ti permette di fare una revisione del codice o di verificare una funzionalità senza sporcare il tuo ambiente di lavoro principale. Basta un attimo e hai una copia esatta di quello che sta vedendo il tuo collega dall'altra parte del mondo.
Risolvere i conflitti prima che diventino incubi
I conflitti non sono il male assoluto. Sono solo il modo in cui il computer ti dice che non può leggere la tua mente. Se tu hai cambiato la riga 10 di un file e io ho fatto lo stesso, Git non sa quale versione tenere. Quando si verifica un intoppo durante l'aggiornamento, la cosa peggiore che puoi fare è farti prendere dal panico e cancellare cartelle a caso.
Prenditi un momento. Leggi il messaggio di errore. Di solito ti elenca esattamente quali file sono in contrasto. Apri quei file e cerca i marcatori visivi. Vedrai la tua versione e quella del server separate da una linea di segni uguali. Scegli quella corretta, o meglio ancora, scrivi una terza versione che integri entrambe. Una volta fatto, aggiungi il file e prosegui. La calma è la tua arma migliore contro il codice rotto.
Casi d'uso comuni per il Git Pull From A Remote Branch nel quotidiano
Vediamo qualche scenario pratico. Sei in un team che usa GitLab per gestire la produzione. La pipeline di integrazione continua fallisce perché il tuo codice è basato su una versione obsoleta del framework. In questo caso, devi aggiornare la tua base di partenza immediatamente. Non puoi permetterti di ignorare l'evoluzione del repository centrale.
Un altro esempio tipico riguarda le hotfix. C'è un bug critico in produzione e devi risolverlo subito. Ma prima di iniziare, devi assicurarti di avere l'ultimissima versione del codice che è stata effettivamente pubblicata. Scaricare le modifiche dal ramo di produzione è il primo passo obbligatorio. Se inizi a lavorare su una versione vecchia di tre giorni, la tua soluzione potrebbe non funzionare affatto nell'ambiente reale.
Lavorare con repository multipli
In alcuni progetti complessi, potresti avere più di un server remoto. Magari uno è quello ufficiale dell'azienda e l'altro è il tuo fork personale. Sapere come pescare i dati dal ramo giusto è fondamentale. Puoi configurare diversi "remote" e dare a ognuno un nome evocativo. Quando esegui l'aggiornamento, specifichi il nome del server e il nome del ramo. Questo livello di organizzazione separa i professionisti dagli amatori.
C'è poi la questione del tracciamento. Quando crei un nuovo ramo locale, dovresti sempre impostare un ramo di tracciamento remoto. Questo permette al software di sapere automaticamente dove andare a guardare quando scrivi il comando abbreviato. Risparmi tempo e riduci la probabilità di errori di battitura che potrebbero inviare il tuo codice nel posto sbagliato.
Il mito del comando magico
C'è chi pensa che basti aggiungere flag come --force ovunque per risolvere i problemi. È un approccio pericoloso. Forzare un aggiornamento significa dire al sistema di distruggere qualsiasi cosa trovi sul suo cammino per far spazio ai nuovi dati. Va bene se hai fatto un disastro totale localmente e vuoi ricominciare da zero, ma è una mossa nucleare. Usala solo se sei consapevole che perderai ogni modifica non salvata.
La verità è che il software è progettato per proteggerti. Se ti impedisce di fare qualcosa, di solito c'è un motivo valido. Invece di forzare, prova a capire perché c'è un blocco. Spesso basta un semplice "stash" per mettere momentaneamente da parte il tuo lavoro, pulire il terreno, aggiornare e poi recuperare le tue modifiche. È un modo molto più civile di gestire lo sviluppo software.
Errori da evitare assolutamente
L'errore più frequente è dimenticarsi di fare un aggiornamento prima di iniziare una nuova sessione di lavoro. Ti metti a scrivere codice per quattro ore su una versione vecchia. Quando finalmente provi a sincronizzare, scopri che il file su cui hai lavorato è stato completamente riscritto da un altro. A quel punto, integrare le tue modifiche diventa un lavoro manuale lungo e noioso. La prima cosa da fare ogni mattina è scaricare lo stato attuale del progetto.
Un altro sbaglio è ignorare i messaggi del terminale. Git è molto logorroico e ti dà quasi sempre la soluzione al problema nel testo dell'errore. Molti utenti chiudono la finestra appena vedono una riga rossa. Leggi. Spesso ti suggerisce persino il comando esatto da copiare e incollare per sistemare la situazione. Non aver paura di quello che dice il computer.
La trappola dei merge commit giganti
Se aspetti troppo tempo tra un aggiornamento e l'altro, il risultato sarà un merge commit gigantesco che tocca centinaia di file. Questo è un incubo per chi deve fare la revisione del tuo codice. Piccoli aggiornamenti frequenti sono la chiave per mantenere la salute del repository. È come lavare i piatti: se lo fai dopo ogni pasto ci metti due minuti, se aspetti una settimana ti serve un'idropulitrice.
Non confondere pull con fetch
Questo è un punto tecnico su cui molti cadono. Il fetch scarica solo le informazioni ma non cambia i tuoi file. Il pull scarica e prova a unire. Se vuoi solo vedere cosa hanno fatto i tuoi colleghi senza rischiare di rompere il tuo lavoro attuale, usa il fetch. Ti permette di ispezionare le modifiche remote in tutta sicurezza. Solo quando sei pronto a integrare davvero tutto, procedi con l'operazione completa.
Strumenti che semplificano la vita
Sebbene il terminale sia il re, esistono strumenti che aiutano a visualizzare meglio la situazione. Software come GitKraken o le estensioni integrate in VS Code mostrano graficamente dove si trova il tuo ramo rispetto a quello remoto. Vedere i pallini colorati che si allontanano o si incrociano aiuta a capire visivamente la topologia del progetto.
Questi strumenti sono ottimi per risolvere i conflitti. Offrono interfacce a tre colonne dove vedi la tua versione a sinistra, quella remota a destra e il risultato finale al centro. È molto più intuitivo che modificare manualmente i file di testo pieni di freccette e segni matematici. Usa la tecnologia a tuo vantaggio, ma non diventarne schiavo: devi sempre sapere cosa sta succedendo dietro l'interfaccia grafica.
Automazione e script
Se lavori su molti repository contemporaneamente, potresti voler automatizzare il processo. Esistono script che ciclicamente controllano lo stato dei rami remoti e ti avvisano se ci sono novità. Questo ti permette di essere sempre sul pezzo senza dover scrivere comandi ogni cinque minuti. Tuttavia, l'automazione del merge vero e proprio è sconsigliata. Vuoi sempre essere tu a dare l'ok finale prima che il codice di qualcun altro entri nel tuo spazio di lavoro.
Integrità dei dati
Git è incredibilmente resistente. È quasi impossibile perdere dati in modo permanente se hai fatto almeno un commit. Anche se sbagli un'operazione di sincronizzazione e sembra che tutto sia sparito, esiste un registro interno chiamato "reflog" che tiene traccia di ogni movimento della testina del repository. Se succede un disastro, puoi quasi sempre tornare indietro nel tempo a uno stato precedente. Questa rete di sicurezza è ciò che permette ai programmatori di sperimentare senza troppa ansia.
Passi pratici per una gestione perfetta
Per dominare questa procedura, segui questo schema mentale ogni volta che ti siedi davanti alla tastiera:
- Controlla lo stato attuale del tuo lavoro. Se hai modifiche in sospeso, decidi se fare il commit o metterle nello "stash". Mai provare a scaricare roba nuova con un'area di lavoro sporca.
- Identifica la sorgente. Assicurati di sapere quale ramo remoto è quello di riferimento per il tuo compito attuale.
- Esegui un fetch preventivo. Guarda cosa è successo sul server senza toccare i tuoi file locali. Questo ti dà un vantaggio psicologico.
- Procedi con l'integrazione. Se preferisci una storia pulita, usa l'opzione rebase. Se preferisci la tracciabilità dei merge, usa il metodo standard.
- Verifica i test. Una volta completato l'aggiornamento, compila il progetto e lancia i test automatizzati. Non dare mai per scontato che l'unione automatica non abbia rotto qualche logica sottile.
- Se ci sono conflitti, affrontali subito. Non lasciarli lì a marcire mentre continui a scrivere altro codice. Risolvi, aggiungi i file e termina l'operazione.
Sviluppare questa routine trasformerà il modo in cui interagisci con il team. Non sarai più quello che "rompe la build" o che manda in crash il server di test. Diventerai quello affidabile, capace di navigare tra i rami remoti con la precisione di un chirurgo. Alla fine, la programmazione è per il 20% scrivere nuovo codice e per l'80% gestire quello che esiste già. Gestire bene i flussi di dati remoti è la competenza che ti permette di eccellere in quell'80% fondamentale.
Ricorda che ogni comando che scrivi lascia una traccia. Scrivi una storia di cui puoi andare fiero, fatta di commit chiari e integrazioni pulite. Il tuo io del futuro, tra sei mesi, ti ringrazierà quando dovrà rileggere quei log per capire perché una funzione ha smesso di rispondere correttamente. La padronanza degli strumenti è il primo passo verso l'artigianato digitale di alto livello. Non smettere mai di esplorare le opzioni che il sistema ti offre; c'è sempre un modo più efficiente per fare quello che stai facendo ora. Se impari a trattare il codice degli altri con lo stesso rispetto che porti al tuo, il successo del progetto è praticamente garantito. È una questione di metodo, disciplina e un pizzico di curiosità tecnica. Successo assicurato.



