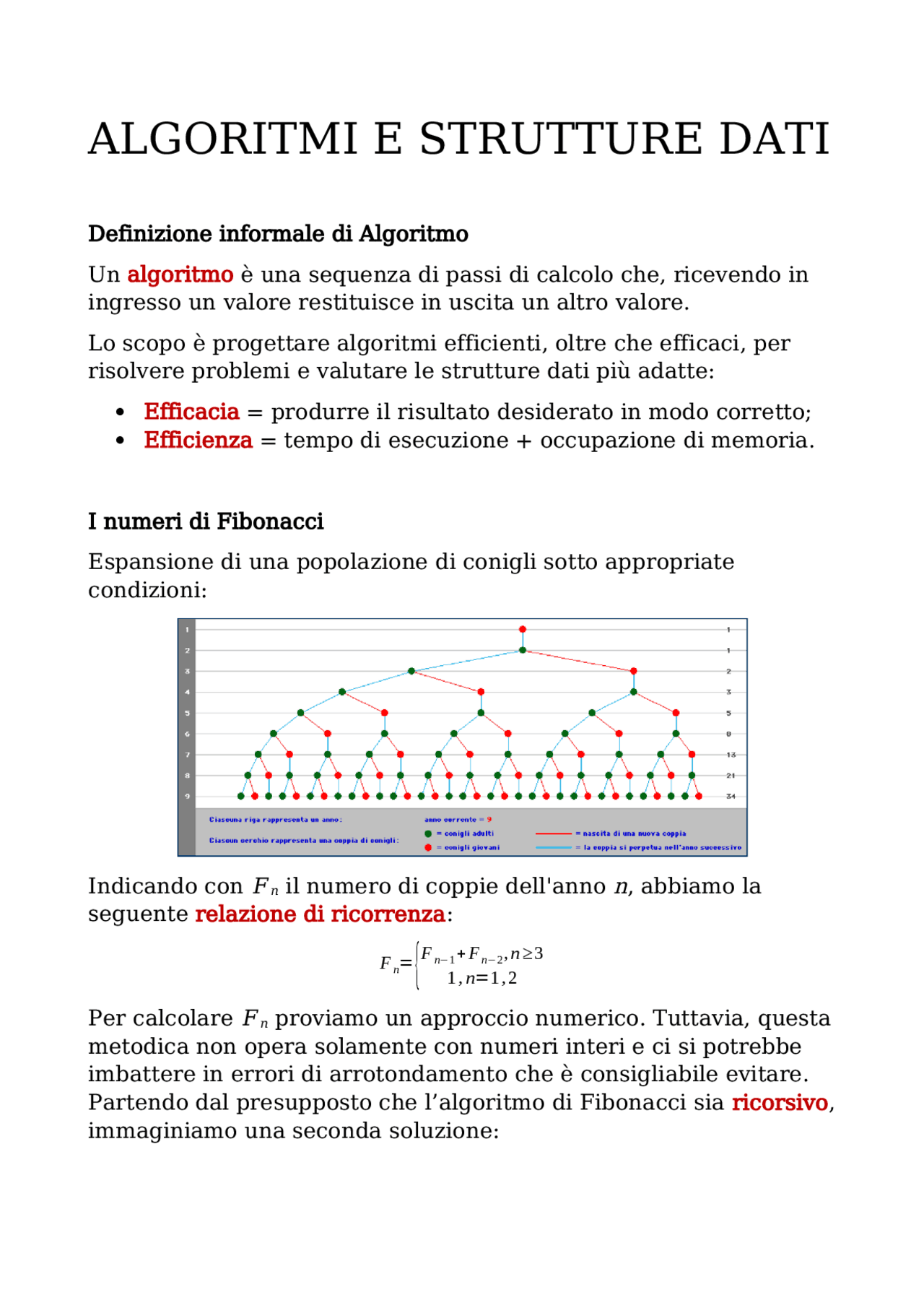
Ho visto decine di sviluppatori junior e professionisti in fase di riconversione chiudersi in una stanza per tre mesi con la convinzione che leggere ogni singola pagina di un Introduzione Agli Algoritmi E Strutture Dati PDF li avrebbe resi pronti per Google o per gestire l'infrastruttura di una startup ad alta crescita. Si presentano al colloquio o al primo giorno di progetto sapendo tutto sulla teoria della complessità computazionale, ma non appena gli chiedi di ottimizzare un processo di importazione dati che sta bruciando 500 euro al giorno in risorse cloud, vanno nel panico. Il fallimento tipico avviene così: passi settimane a memorizzare come bilanciare un albero Red-Black su carta, poi arrivi sul lavoro e scrivi un ciclo annidato che trasforma un'operazione semplice in un incubo da $O(n^2)$ perché non hai capito come i dati vengono effettivamente letti dalla memoria. Hai perso tempo, l'azienda ha perso soldi e la tua reputazione professionale ne risente prima ancora di iniziare.
Il mito della memorizzazione mnemonica in Introduzione Agli Algoritmi E Strutture Dati PDF
L'errore più costoso che puoi commettere è trattare questo argomento come una materia umanistica da imparare a memoria. Molti scaricano un manuale e iniziano a studiare le definizioni dei grafi o le proprietà dei mucchi come se dovessero superare un esame di storia. Non serve a nulla. Nella realtà produttiva, non scriverai quasi mai una tua implementazione di un algoritmo di ordinamento. Quello che conta è capire la differenza tra la teoria e come il processore gestisce i dati.
Ho gestito un team dove un ragazzo aveva passato mesi su un Introduzione Agli Algoritmi E Strutture Dati PDF accademico. Sapeva tutto sulla teoria, ma quando ha dovuto implementare una ricerca su un dataset di milioni di utenti, ha scelto una struttura dati che sulla carta era perfetta ma che causava continui "cache miss". Il risultato? Il sistema era cinque volte più lento di una soluzione teoricamente meno efficiente ma più amica dell'hardware. La soluzione non è studiare di più, è studiare con l'obiettivo di capire l'impatto fisico del codice. Devi smettere di guardare le astrazioni e iniziare a pensare a come i bit si muovono nei bus di sistema. Se non capisci questo, quel file che stai leggendo è solo un ammasso di concetti sterili che non ti aiuteranno a risolvere problemi reali sotto pressione.
Ignorare la località dei dati costa caro in termini di performance
C'è un malinteso diffuso per cui la complessità asintotica sia l'unica metrica che conta. Se vedi $O(1)$ pensi che sia istantaneo. Se vedi $O(n)$ pensi che sia lento. Questo è il motivo per cui molti falliscono miseramente nella progettazione di sistemi ad alte prestazioni. In un contesto moderno, una scansione lineare su un array contiguo può essere molto più veloce di una ricerca in una lista collegata, anche se la lista avrebbe vantaggi teorici per certe inserzioni.
Questo accade perché le moderne CPU usano le cache. Quando carichi un dato, il processore non prende solo quel byte, prende l'intera riga di cache. Se i tuoi dati sono sparsi ovunque nella RAM — come accade con molte strutture dati dinamiche spiegate nei corsi base — costringi la CPU ad aspettare che i dati arrivino dalla memoria principale. Sono cicli di clock buttati via. In un caso reale che ho seguito, passare da una struttura a puntatori sparsi a un semplice buffer di memoria contiguo ha ridotto i tempi di esecuzione da 12 secondi a meno di 2 secondi, senza cambiare la logica dell'algoritmo. La teoria ti dice cosa è possibile, ma la pratica ti dice cosa è veloce. Se ignori il modo in cui i dati sono disposti fisicamente, stai solo giocando con la matematica, non stai facendo ingegneria del software.
L'ossessione per i casi limite che non si verificano mai
Passiamo troppo tempo a preoccuparci del caso peggiore assoluto, quello che accade una volta su un miliardo. Certo, è utile sapere che un hash table può degenerare in una lista collegata se le collisioni sono troppe, ma se passi tre settimane a implementare un sistema di protezione contro gli attacchi di collisione quando il tuo software gira in una rete privata sicura, stai buttando i soldi dello stipendio che ti pagano.
L'approccio giusto è guardare i dati medi che il tuo sistema riceverà. Molti sviluppatori scelgono algoritmi complessi per gestire scenari che non vedranno mai nella loro intera carriera. Ho visto startup fallire perché gli ingegneri passavano il tempo a rendere il sistema "scalabile all'infinito" usando strutture dati ipersofisticate prima ancora di avere mille utenti. Il costo di manutenzione di quel codice era così alto che non riuscivano a implementare nuove funzionalità richieste dal mercato. Devi imparare a scegliere lo strumento più semplice che risolve il problema per il 99% dei tuoi utenti, lasciando una via d'uscita per quel restante 1%.
## La trappola del fai-da-te invece di usare le librerie standard
Questo è l'errore che separa i dilettanti dai professionisti che sanno quanto costa un'ora di lavoro. Molti pensano che dopo aver letto un Introduzione Agli Algoritmi E Strutture Dati PDF debbano dimostrare la loro bravura scrivendo da soli la propria versione di una mappa hash o di un algoritmo di compressione.
- Identifica il problema di performance o di organizzazione dati.
- Cerca l'implementazione della libreria standard del tuo linguaggio (STL in C++, Collections in Java, ecc.).
- Leggi la documentazione per capire le garanzie di complessità e l'occupazione di memoria.
- Usa quella versione, perché è stata testata da migliaia di sviluppatori e ottimizzata per quel compilatore specifico.
Ho visto un'azienda spendere 40.000 euro in consulenze per trovare un bug in un sistema di allocazione di memoria "personalizzato" che un ingegnere aveva scritto convinto di poter fare meglio della libreria standard. Il bug era una condizione di gara sottile che si presentava solo sotto carico estremo. Se avesse usato gli strumenti standard, quel problema non sarebbe mai esistito. La tua bravura non si vede da quanto codice scrivi, ma da quanto poco ne scrivi per ottenere il risultato massimo.
Perché i test di performance battono la teoria ogni volta
Se non misuri, non sai nulla. Molti programmatori prendono decisioni basate su quello che ricordano dai tempi dell'università senza mai avviare un profiler. Puoi pensare che un algoritmo sia migliore di un altro, ma finché non lo metti sotto carico con dati realistici, stai solo tirando a indovinare.
Il pericolo dei micro-benchmark fuorvianti
Un altro errore è basarsi su test troppo piccoli. Misurare quanto tempo ci mette un algoritmo a ordinare 100 numeri non ti dice nulla su come si comporterà quando ne dovrà ordinare 100 milioni. I colli di bottiglia cambiano radicalmente quando i dati smettono di stare nella cache L3 e devono finire sulla RAM o, peggio, sul disco.
Confronto tra approccio accademico e approccio pragmatico
Vediamo come cambia il lavoro di uno sviluppatore quando smette di seguire ciecamente la teoria e inizia a ragionare sui costi reali.
Immaginiamo di dover gestire un sistema di messaggistica dove dobbiamo trovare rapidamente se un utente è online in una lista di milioni di profili. Lo sviluppatore che segue l'approccio accademico apre il suo libro e decide di usare un albero di ricerca binario bilanciato. Pensa che $O(\log n)$ sia ottimo. Spende tre giorni a scrivere il codice per il bilanciamento, gestendo i puntatori e i casi di rotazione dei nodi. Quando il sistema va in produzione, scopre che per ogni ricerca deve saltare da una parte all'altra della memoria per seguire i puntatori dei nodi, causando ritardi pesanti a causa dei tempi di accesso alla RAM. Il codice è complesso, difficile da leggere e lento a causa della frammentazione della memoria.
Lo sviluppatore pragmatico invece sa che la velocità d'accesso conta più del numero teorico di operazioni. Decide di usare un array ordinato se i dati non cambiano spesso, sfruttando la ricerca binaria che lavora su memoria contigua. Oppure, se gli inserimenti sono frequenti, usa un'hash table della libreria standard ben dimensionata. In meno di un'ora ha finito il compito. Il suo codice è composto da tre righe, è incredibilmente veloce perché sfrutta la cache del processore e non ha bug perché non ha dovuto implementare logiche complesse di gestione dei puntatori. Il primo sviluppatore ha prodotto un debito tecnico che richiederà ore di debug; il secondo ha prodotto una soluzione solida e scalabile in una frazione del tempo.
La gestione della memoria non è un dettaglio opzionale
Molti pensano che con i linguaggi moderni che hanno il Garbage Collector non serva più capire come funziona l'allocazione delle risorse. Non c'è niente di più sbagliato. Se crei migliaia di piccoli oggetti all'interno di un ciclo critico perché la struttura dati scelta lo richiede, stai costringendo il sistema a perdere tempo per pulire la memoria.
In un progetto di analisi dati finanziari in tempo reale, il sistema si bloccava ogni 30 secondi per circa mezzo secondo. Era inaccettabile. Il motivo? Lo sviluppatore aveva usato una struttura dati che creava un nuovo oggetto per ogni singola transazione. Il Garbage Collector non riusciva a stare dietro a quella mole di spazzatura e doveva fermare l'intero programma per pulire. Abbiamo risolto il problema riutilizzando gli oggetti (object pooling) e usando array di tipi primitivi. La logica algoritmica era identica, ma il modo in cui gestivamo la memoria ha fatto la differenza tra un prodotto fallimentare e uno di successo. Non puoi essere un bravo programmatore se non capisci cosa succede "sotto il cofano" del tuo linguaggio preferito.
Controllo della realtà
Smettiamola di raccontarci favole: non diventerai un esperto leggendo un documento PDF o guardando qualche video su YouTube. La padronanza di questi concetti non arriva dalla comprensione intellettuale di un algoritmo, ma dalle ore passate a fare debugging quando le cose non funzionano come previsto. Il mercato è pieno di persone che sanno spiegare il QuickSort sulla lavagna ma che si bloccano davanti a un file di log da 10 gigabyte perché non sanno come processarlo senza saturare la RAM.
Per avere successo davvero, devi accettare che la teoria è solo una mappa, e la mappa non è il territorio. Ti servirà sporcarti le mani con i profiler, imparare a leggere il codice sorgente delle librerie che usi e, soprattutto, avere l'umiltà di scartare una soluzione elegante se quella "brutta" e semplice funziona meglio. Non c'è gloria nel risolvere un problema in modo complesso se esiste una strada più breve. Il tempo è la risorsa più preziosa che hai, non sprecarlo inseguendo una perfezione teorica che non serve a nessuno. Se vuoi davvero fare il salto di qualità, inizia a misurare ogni singola scelta che fai e smetti di fidarti dell'intuizione o delle slide del professore di turno. Solo allora capirai veramente cosa significa ottimizzare un sistema.



