L'ho visto accadere in una multinazionale della logistica meno di un anno fa. Un team di data scientist entusiasti aveva appena finito di addestrare un modello di previsione dell'abbandono dei clienti. Erano fieri dei loro risultati: una curva bellissima, un valore numerico vicino allo 0.92 ottenuto usando i pacchetti standard per gestire ROC And AUC In R e una presentazione PowerPoint pronta per il consiglio di amministrazione. Sulla carta, il modello era un successo totale. Peccato che, una volta messo in produzione, l’azienda abbia iniziato a perdere migliaia di euro ogni settimana. Il motivo? Avevano ottimizzato il numero sbagliato, ignorando che una metrica di probabilità pura non tiene conto del costo di un falso allarme rispetto al costo di un cliente perso. Hanno scambiato la capacità discriminante del modello per una strategia di business, un errore che vedo ripetere costantemente da chi pensa che la programmazione sia solo una questione di sintassi corretta.
Il fallimento del valore unico nel calcolo di ROC And AUC In R
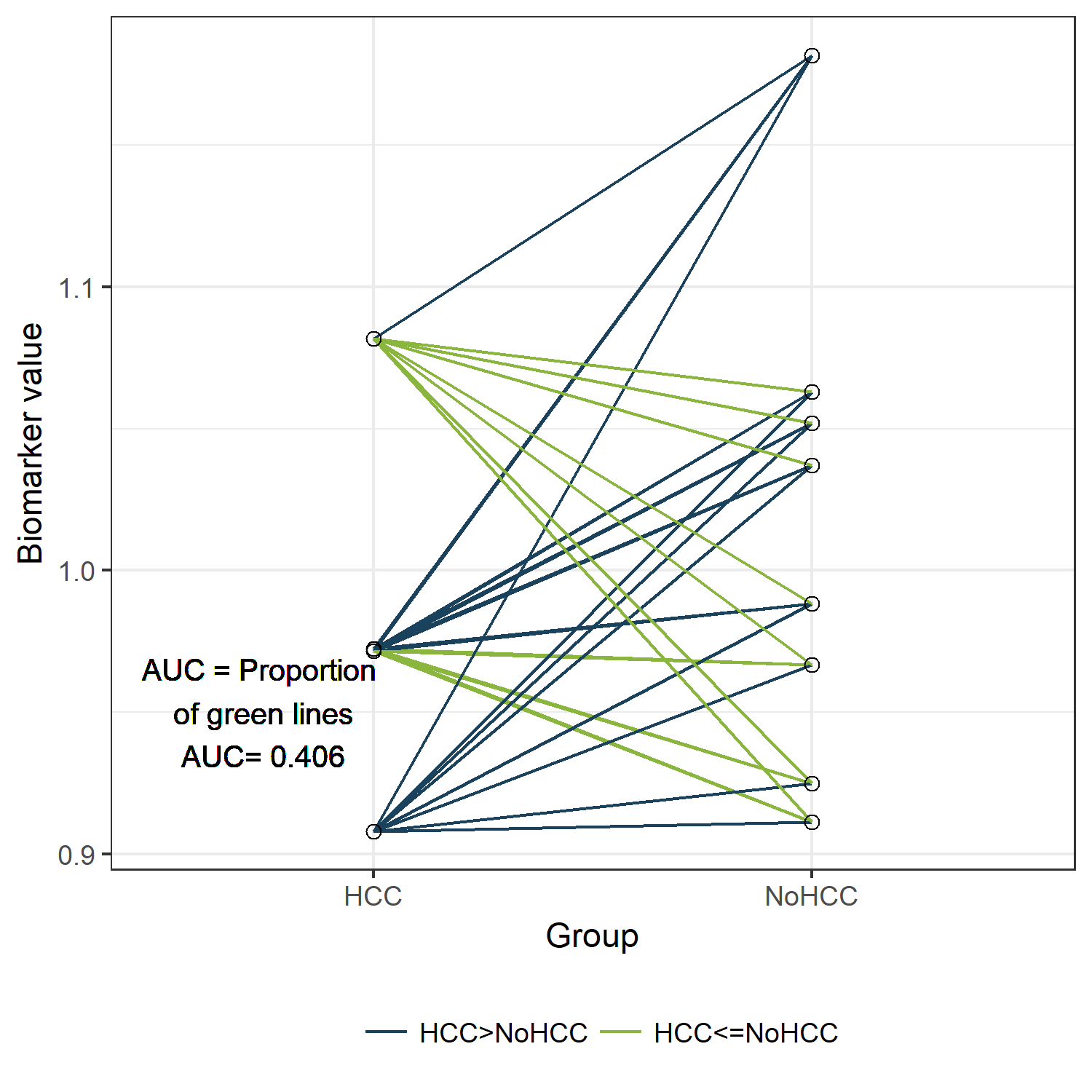
Il primo grande abbaglio è credere che un singolo numero possa dirti se il tuo lavoro è finito. Molti professionisti alle prime armi caricano le loro librerie, lanciano il comando e se leggono 0.85 si sentono al sicuro. Non funziona così. Quell'area sotto la curva rappresenta la probabilità che il modello assegni un punteggio più alto a un caso positivo scelto a caso rispetto a uno negativo. È una misura di ordinamento, non di accuratezza. Ho lavorato su progetti in cui un punteggio di 0.70 era un trionfo perché il segnale nei dati era debolissimo, e su altri dove 0.95 era un segnale d'allarme rosso fuoco perché indicava un leak di dati pazzesco.
Quando ti affidi ciecamente al valore finale della funzione, dimentichi di guardare la forma della curva. Ho visto modelli con lo stesso valore numerico comportarsi in modi opposti. Uno era eccellente nell'identificare i casi facili ma pessimo su quelli critici, l'altro era mediocre ovunque ma costante. Se non analizzi dove la curva "spancia", non saprai mai se il tuo modello è utile per le decisioni reali. Il costo di questo errore non è solo accademico; si traduce in decisioni operative sbagliate basate su un numero che non ha un contesto fisico o monetario.
L'illusione dei dati sbilanciati e l'uso di ROC And AUC In R nei titoli dei report
Un errore che distrugge la credibilità di un analista è presentare risultati strabilianti su dataset dove la classe positiva rappresenta meno dell'1% del totale. In questi scenari, questa metrica diventa pericolosamente ottimista. Se stai cercando di prevedere frodi bancarie o malattie rare, la curva salirà verso l'alto molto velocemente, dandoti l'illusione di una precisione che non hai.
Perché la curva ti sta mentendo
Il problema tecnico risiede nel fatto che la specificità — ovvero la capacità di identificare correttamente i casi negativi — domina il calcolo quando i "negativi" sono la stragrande maggioranza. Puoi avere migliaia di falsi positivi che rovinano l'operatività aziendale, ma la tua curva sembrerà comunque ottima perché, in proporzione ai milioni di casi negativi correttamente identificati, quei fallimenti sembrano rumore statistico. Se il tuo capo legge che il modello è quasi perfetto grazie all'analisi di ROC And AUC In R che hai inserito nel titolo del report tecnico, ma poi il team operativo deve gestire 500 falsi allarmi al giorno per trovare una sola frode, verrai licenziato. O dovresti esserlo. In questi casi, devi smettere di guardare quella curva e passare alla Precision-Recall curve. È meno "sexy" da presentare perché i numeri sono quasi sempre più bassi, ma è l'unica cosa che ti dice la verità su quanto stai effettivamente aiutando il business.
Ignorare il punto di cut-off sacrifica il profitto
La maggior parte dei pacchetti che gestiscono questo processo restituisce una probabilità tra 0 e 1. Molti utenti prendono quella probabilità e usano lo standard di 0.5 come soglia di decisione. Questo è il modo più rapido per fallire. La curva ti mostra le prestazioni su tutte le possibili soglie, ma in produzione ne userai solo una. Scegliere quella soglia basandosi sulla "bellezza" della curva invece che sui costi economici è pura follia.
Immagina di lavorare per una compagnia aerea. Un falso positivo significa negare l'imbarco a un passeggero fedele per errore (costo altissimo in termini di reputazione e rimborsi). Un falso negativo significa far salire qualcuno con un biglietto clonato (costo del pasto e del carburante). Le conseguenze non sono uguali. Ho visto aziende perdere milioni perché il team tecnico ha scelto il punto della curva più vicino all'angolo in alto a sinistra (il metodo di Youden) senza consultare il reparto vendite. Quel punto è matematicamente elegante ma economicamente spesso irrilevante. Devi mappare ogni punto della curva a una matrice di costi e benefici monetari. Solo allora saprai dove posizionarti davvero.
Prima e Dopo: come cambia la realtà con un approccio consapevole
Per capire meglio, guardiamo come si muove un team che non sa quello che sta facendo rispetto a uno che ha esperienza sul campo.
Prima: l'approccio ingenuo Il team riceve i dati storici delle vendite. Pulisce il dataset, addestra una foresta casuale e calcola l'area sotto la curva. Ottengono 0.88. Esultano. Generano le previsioni per il mese successivo applicando la soglia standard di 0.5. Il reparto marketing invia coupon di sconto del 50% a tutti i clienti identificati come "a rischio abbandono". Dopo un mese, i dati mostrano che le vendite sono aumentate, ma il profitto netto è crollato. Perché? Perché il modello ha incluso moltissimi clienti che avrebbero acquistato comunque a prezzo pieno (falsi positivi). Il team ha sprecato budget dando sconti a chi non ne aveva bisogno, tutto perché si è fidato di un numero aggregato senza testare la calibrazione delle probabilità.
Dopo: l'approccio professionale Il team riceve gli stessi dati. Calcola la metrica ma non si ferma lì. Analizza la curva per segmenti di clientela. Scopre che per i clienti "VIP" il modello è meno preciso. Invece di usare una soglia fissa, calcola il valore atteso per ogni cliente. Se il costo del coupon è 10 euro e il margine perso dal cliente che se ne va è 100 euro, la soglia di intervento viene calcolata per massimizzare il profitto residuo, non per massimizzare l'area sotto una curva teorica. Decidono di intervenire solo quando la probabilità supera lo 0.72 per i VIP e lo 0.45 per i clienti occasionali. Risultato: il tasso di abbandono scende, i coupon inviati sono la metà rispetto a prima e il margine operativo cresce del 12%. La differenza non sta nell'algoritmo usato, ma nel modo in cui i risultati di quella stessa analisi sono stati interpretati e piegati alle necessità del mondo fisico.
Il mito della stabilità temporale
Un altro errore che ho visto costare carissimo è dare per scontato che la tua curva rimanga identica nel tempo. I dati cambiano. Il comportamento umano cambia. Se hai calcolato le prestazioni del tuo modello su dati di due anni fa, quelle metriche oggi sono spazzatura.
Il monitoraggio post-distribuzione
Molti programmatori pensano che una volta scritto lo script e verificata la curva, il lavoro sia finito. In realtà, è proprio lì che inizia il pericolo. Ho gestito sistemi di punteggio del credito dove la capacità discriminante del modello degradava di un punto percentuale ogni mese. Se non avessimo monitorato la curva su base settimanale, ci saremmo ritrovati dopo un anno ad approvare prestiti a persone che non potevano ripagarli, basandoci su una fiducia cieca in un test fatto mesi prima. Non puoi limitarti a calcolare la metrica una volta; devi creare un sistema che la ricalcoli continuamente sui nuovi dati in arrivo (ground truth) per intercettare il momento esatto in cui il modello inizia a "derapare".
La trappola della complessità inutile
C'è questa tendenza ossessiva a cercare il pacchetto più complicato o l'algoritmo più recente per spremere uno 0.001 in più dall'area sotto la curva. È una perdita di tempo totale. Nella mia carriera, non ho mai visto un business fallire perché l'area sotto la curva era 0.84 invece di 0.841. Ho visto invece fallire progetti perché il modello era così complesso da non poter essere spiegato ai regolatori o perché richiedeva tempi di calcolo incompatibili con le necessità dell'azienda.
Spesso, un modello di regressione logistica ben calibrato batte un'architettura deep learning complessa semplicemente perché è più facile da correggere quando le cose vanno male. Se passi settimane a cercare di migliorare la curva usando tecniche di ensemble oscure, stai rubando tempo alla comprensione del problema di fondo. Il successo non deriva dalla perfezione della curva, ma dalla sua robustezza. Preferisco un modello che mantiene uno 0.80 costante per due anni a uno che tocca 0.90 oggi ma crolla a 0.60 alla prima variazione del mercato.
Strumenti e procedure per non sbagliare
Quando si lavora con questi strumenti, bisogna seguire un protocollo rigido. Non si tratta di scrivere codice elegante, ma di non farsi ingannare dai propri dati.
- Dividere sempre i dati in training, validation e test set, ma assicurarsi che la divisione sia temporale se i dati hanno una componente cronologica. Usare una cross-validation casuale su dati temporali è il modo più veloce per sovrastimare la bontà della tua analisi.
- Controllare sempre la calibrazione del modello. Se il tuo modello dice che un evento ha il 70% di probabilità di accadere, quell'evento deve accadere circa 7 volte su 10 nella realtà. Una curva perfetta può nascondere un modello totalmente scalibrato.
- Visualizzare sempre la matrice di confusione accanto alla curva. Ti serve per capire quanti errori stai facendo e di che tipo sono. Un errore di tipo I e un errore di tipo II non hanno mai lo stesso peso nel mondo degli affari.
- Testare il modello su sottogruppi specifici. Ho visto modelli con ottimi punteggi generali che però erano totalmente inutili (o discriminatori) su specifiche aree geografiche o fasce d'età.
Controllo della realtà
Smettiamola di raccontarci favole. La verità è che a nessuno là fuori interessa quanto sia bella la tua curva ROC o quanto sia alto il tuo AUC. Al tuo cliente o al tuo capo interessa solo se quel modello prende decisioni che portano valore. Se passi le giornate a ottimizzare decimali in R senza capire l'impatto economico di un falso positivo, non sei un data scientist, sei un hobbista costoso.
Non esiste una formula magica che trasformi un cattivo set di dati in un successo commerciale solo perché hai usato la libreria giusta. Se i tuoi dati sono sporchi, distorti o semplicemente non contengono le informazioni necessarie per prevedere l'evento, puoi calcolare tutte le aree sotto la curva che vuoi, ma otterrai solo spazzatura ben confezionata. Il lavoro vero non è far girare lo script; è capire quando quel numero che vedi sullo schermo è un segnale reale e quando è solo un miraggio statistico dovuto al fatto che hai torturato i dati finché non hanno confessato quello che volevi sentire. Non cercare la perfezione numerica, cerca la solidità operativa. È meno gratificante per l'ego, ma è l'unica cosa che ti garantisce una carriera a lungo termine in questo settore.



